冰山上的博客,更新速度之快,令我乍叹不已,我以为我算是勤劳的,想不到,他更是属于勤劳中的勤劳分子。。
以下内容又是COPY于他的网站,看来,他关注的部分内容还是比我高档,我仍然沉迷于一些小技巧,而忽略了一些大的东西。
心有多大,舞台有多大,其实这对技术人员来说非常重要,如果你只注重于一小块技术,那么在大的方面,你永远不会有进步。
扯远了。。不过以下一些小技巧我真的大部分都没有用过,所以我才会贴出来,让大家一起学习一下,如果知道的就直接跳过,当我没说。
内容如下:http://xinsync.xju.edu.cn/index.php/archives/4719
前言:
实验的数据表如下定义:
mysql> desc tbl_name;
+-------+--------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-------+--------------+------+-----+---------+-------+
| uid | int(11) | NO | | NULL | |
| sid | mediumint(9) | NO | | NULL | |
| times | mediumint(9) | NO | | NULL | |
+-------+--------------+------+-----+---------+-------+
3 rows in set (0.00 sec)
存储引擎是MyISAM,里面有10,000条数据。
一、”\G”的作用
mysql> select * from tbl_name limit 1;
+--------+--------+-------+
| uid | sid | times |
+--------+--------+-------+
| 104460 | 291250 | 29 |
+--------+--------+-------+
1 row in set (0.00 sec)
mysql> select * from tbl_name limit 1\G;
*************************** 1. row ***************************
uid: 104460
sid: 291250
times: 29
1 row in set (0.00 sec)
有时候,操作返回的列数非常多,屏幕不能一行显示完,显示折行,试试”\G”,把列数据逐行显示(”\G”挽救了我,以前看explain语句横向显示不全折行看起来巨费劲,还要把数据和列对应起来)。
二、”Group by”的”隐形杀手”
mysql> explain select uid,sum(times) from tbl_name group by uid\G;
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: tbl_name
type: ALL
possible_keys: NULL
key: NULL
key_len: NULL
ref: NULL
rows: 10000
Extra: Using temporary; Using filesort
1 row in set (0.00 sec)
mysql> explain select uid,sum(times) from tbl_name group by uid order by null\G;
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: tbl_name
type: ALL
possible_keys: NULL
key: NULL
key_len: NULL
ref: NULL
rows: 10000
Extra: Using temporary
1 row in set (0.00 sec)
默认情况下,Group by col会对col字段进行排序,这就是为什么第一语句里面有Using filesort的原因,如果你不需要对col字段进行排序,加上order by null吧,要快很多,因为filesort很慢的。
三、大批量数据插入
最高效的大批量插入数据的方法:
load data infile ‘/path/to/file’ into table tbl_name;
如果没有办法先生成文本文件或者不想生成文本文件,可以一次插入多行:
insert into tbl_name values (1,2,3),(4,5,6),(7,8,9)…
注意一条sql语句的最大长度是有限制的。如果还不想这样,可以试试MySQL的prepare,应该都会比硬生生的逐条插入要快许多。
如果数据表有索引,建议先暂时禁用索引:
alter table tbl_name disable keys;
插入完毕之后再激活索引:
alter table tbl_name enable keys;
对MyISAM表尤其有用。避免每插入一条记录系统更新一下索引。
四、最快复制表结构方法
mysql> create table clone_tbl select * from tbl_name limit 0;
Query OK, 0 rows affected (0.08 sec)
只会复制表结构,索引不会复制,如果还要复制数据,把limit 0去掉即可。
五、加引号和不加引号区别
给数据表tbl_name添加索引:
mysql> create index uid on tbl_name(uid);
测试如下查询:
mysql> explain select * from tbl_name where uid = '1081283900'\G;
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: tbl_name
type: ref
possible_keys: uid
key: uid
key_len: 4
ref: const
rows: 143
Extra:
1 row in set (0.00 sec)
我们在整型字段的值上加索引,是可以用到索引的,网上不少人误传在整型字段上加引号无法使用索引。修改uid字段类型为varchar(12):
mysql> alter table tbl_name change uid uid varchar(12) not null;
测试如下查询:
mysql> explain select * from tbl_name where uid = 1081283900\G;
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: tbl_name
type: ALL
possible_keys: uid
key: NULL
key_len: NULL
ref: NULL
rows: 10000
Extra: Using where
1 row in set (0.00 sec)
我们在查询值上不加索引,结果索引无法使用,注意安全。
六、前缀索引
有时候我们的表中有varchar(255)这样的字段,而且我们还要对该字段建索引,一般没有必要对整个字段建索引,建立前8~12个字符的索引应该就够了,很少有连续8~12个字符都相等的字段。
为什么?更短的索引意味索引更小、占用CPU时间更少、占用内存更少、占用IO更少和很更好的性能。
七、MySQL索引使用方式
MySQL在一个查询中只能用到一个索引(5.0以后版本引入了index_merge合并索引,对某些特定的查询可以用到多个索引,具体查考[中文] [英文]),所以要根据查询条件建立联合索引,联合索引只有第一位的字段在查询条件中能才能使用到。
如果MySQL认为不用索引比用索引更快的话,那么就不会用索引。
mysql> create index times on tbl_name(times);
Query OK, 10000 rows affected (0.10 sec)
Records: 10000 Duplicates: 0 Warnings: 0
mysql> explain select * from tbl_name where times > 20\G;
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: tbl_name
type: ALL
possible_keys: times
key: NULL
key_len: NULL
ref: NULL
rows: 10000
Extra: Using where
1 row in set (0.00 sec)
mysql> explain select * from tbl_name where times > 200\G;
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: tbl_name
type: range
possible_keys: times
key: times
key_len: 3
ref: NULL
rows: 1599
Extra: Using where
1 row in set (0.00 sec)
数据表中times字段绝大多数都比20大,所以第一个查询没有用索引,第二个才用到索引.
一直在关注着MYSQL的优化工作,但却也从来没有从硬件方面进行过探讨,前段时间有人在群里贴了一个msyql部落的链接,跑上去偷偷看了两眼,发现还是有点料的。以下就是其中的一点料:
http://www.mysqlsystems.com/?p=3
以前一直在MySQL的本家做咨询工作,所以我下面和大家讨论的话题是一个我在工作中经常遇到的问题。
什么时候我们应该升级硬件?什么时候应该修改配置?
作为DBA,老板和公司总是希望我们以最小的投入换来最大的性能(效益)。不过我并没有暗示大家,我接下讨论的话题,会是让各位避免购买硬件。
对于上面的答案很多人肯定会说两者都做,或者只做配置修改。我想我没有给大家出选择题,只是拿出来做任何一个考虑的时候,哪些因素影响着我们。我的回答经常是:
1.使劲优化MySQL服务器和查询语句
先看看别人的例子,或者仔细读一些MySQL的手册吧,这样你可以优化一些非常简单的my.cnf。也许最简单的index提高了几十倍的性能。不要轻易买硬件!
2. 先看看你的硬件整体架构是否平衡?
这个问题比较复杂,需要配合你的系统管理员来做,比较小的公司可能是一个人包了 这两个角色。我曾经去过一个沈阳的ISV那边,他们是一个大数据量,并发的使用MySQL。后来随着业务增加,其中三台IBM的P机放数据库的机器负担非 常重,后来老板下死令要dba调性能。DBA在尝试了很多种手册上的方法后,均无明显效果。后来在很多次交流以后才得知,他们信息中心还有4台机器跑着 Mail服务器,任务量非常轻。在建议他们利用上这些机器可能配置的情况下,性能很快就上去了
3. 没办法,服务器全用上了?
这种情况也非常常见,特别是对于那些服务器24小时都有人访问的web公司,如 youtube。如果用一些性能监视工具去监控整个服务器,结果看看一整天的流量和性能图,可能会大跌眼镜,服务并不是每时每刻都非常慢,而是某个特定时 间段,排除网络的原因,服务器备份的时候或者DBA下班的时候设置的半夜Cron工作总是对数据库有非常大的压力。
4. 还是买硬件吧,有什么建议?
性能调优有句老话,没有最好只有更好。一个系统的性能出现问题,是各个环节的累计造成的。用微观经济学的说法就是我们要使用边际成本最高的投入。
下面几种情况可以考虑相应的部件升级,经济危机了,整机成本太高而且是在没有必要。
IO读写太多,也许考虑买一条200块的内存?
增加CPU运算,也许考虑买一台x86的服务器,忘记Sun的CMT吧,因为MySQL的限制,使用不了这么多线程,反倒增加负担。
本内容来自群聊天记录,开花石头吐出来的。。。
取字段注释
SQL代码
- SELECT COLUMN_NAME 列名, DATA_TYPE 字段类型, COLUMN_COMMENT 字段注释
- FROM INFORMATION_SCHEMA.COLUMNS
- WHERE table_name = 'companies'##表名
- AND table_schema = 'testhuicard'##数据库名
- AND column_name LIKE 'c_name'##字段名
-
- SELECT table_name 表名,TABLE_COMMENT 表注释 FROM INFORMATION_SCHEMA.TABLES WHERE table_schema = 'testhuicard' ##数据库名
-
- AND table_name LIKE 'companies'##表名
参考http://dev.mysql.com/doc/refman/5.1/zh/ 今天找到了取mysql表和字段注释的语句
原文:http://www.javauu.com/thread-4678-1-1.html
如果您正在运行使用MySQL的Web应用程序,那么它把密码或者其他敏感信息保存在应用程序里的机会就很大。保护这些数据免受黑客或者窥探者的获取是一个令人关注的重要问题,因为您既不能让未经授权的人员使用或者破坏应用程序,同时还要保证您的竞争优势。幸运的是,MySQL带有很多设计用来提供这种类型安全的加密函数。本文概述了其中的一些函数,并说明了如何使用它们,以及它们能够提供的不同级别的安全。
双向加密
就让我们从最简单的加密开始:双向加密。在这里,一段数据通过一个密钥被加密,只能够由知道这个密钥的人来解密。MySQL有两个函数来支持这种类型的加密,分别叫做ENCODE()和DECODE()。下面是一个简单的实例:
mysql> INSERT INTO users (username, password) VALUES ('joe', ENCODE('guessme', 'abracadabra'));
Query OK, 1 row affected (0.14 sec)
其中,Joe的密码是guessme,它通过密钥abracadabra被加密。要注意的是,加密完的结果是一个二进制字符串,如下所示:
mysql> SELECT * FROM users WHERE username='joe';
+----------+----------+
| username | password |
+----------+----------+
| joe | ¡?i??!? |
+----------+----------+
1 row in set (0.02 sec)
abracadabra这个密钥对于恢复到原始的字符串至关重要。这个密钥必须被传递给DECODE()函数,以获得原始的、未加密的密码。下面就是它的使用方法:
mysql> SELECT DECODE(password, 'abracadabra') FROM users WHERE username='joe';
+---------------------------------+
| DECODE(password, 'abracadabra') |
+---------------------------------+
| guessme |
+---------------------------------+
1 row in set (0.00 sec)
应该很容易就看到它在Web应用程序里是如何运行的――在验证用户登录的时候,DECODE()会用网站专用的密钥解开保存在数据库里的密码,并和用户输入的内容进行对比。假设您把PHP用作自己的脚本语言,那么可以像下面这样进行查询:
$query = "SELECT COUNT(*) FROM users WHERE username='$inputUser' AND DECODE(password, 'abracadabra') = '$inputPass'";?>
提示:虽然ENCODE()和DECODE()这两个函数能够满足大多数的要求,但是有的时候您希望使用强度更高的加密手段。在这种情况下,您可以使用AES_ENCRYPT()和AES_DECRYPT()函数,它们的工作方式是相同的,但是加密强度更高。
单向加密
单向加密与双向加密不同,一旦数据被加密就没有办法颠倒这一过程。因此密码的验证包括对用户输入内容的重新加密,并将它与保存的密文进行比对,看是否匹配。一种简单的单向加密方式是MD5校验码。MySQL的MD5()函数会为您的数据创建一个“指纹”并将它保存起来,供验证测试使用。下面就是如何使用它的一个简单例子:
mysql> INSERT INTO users (username, password) VALUES ('joe', MD5('guessme'));
Query OK, 1 row affected (0.00 sec)
mysql> SELECT * FROM users WHERE username='joe';
+----------+----------------------------------+
| username | password |
+----------+----------------------------------+
| joe | 81a58e89df1f34c5487568e17327a219 |
+----------+----------------------------------+
1 row in set (0.02 sec)
现在您可以测试用户输入的内容是否与已经保存的密码匹配,方法是取得用户输入密码的MD5校验码,并将它与已经保存的密码进行比对,就像下面这样:
mysql> SELECT COUNT(*) FROM users WHERE username='joe' AND password=MD5('guessme');
+----------+
| COUNT(*) |
+----------+
| 1 |
+----------+
1 row in set (0.00 sec)
或者,您考虑一下使用ENCRYPT()函数,它使用系统底层的crypt()系统调用来完成加密。这个函数有两个参数:一个是要被加密的字符串,另一个是双(或者多)字符的“salt”。它然后会用salt加密字符串;这个salt然后可以被用来再次加密用户输入的内容,并将它与先前加密的字符串进行比对。下面一个例子说明了如何使用它:
mysql> INSERT INTO users (username, password) VALUES ('joe', ENCRYPT('guessme', 'ab'));
Query OK, 1 row affected (0.00 sec)
mysql> SELECT * FROM users WHERE username='joe';
+----------+---------------+
| username | password |
+----------+---------------+
| joe | ab/G8gtZdMwak |
+----------+---------------+
1 row in set (0.00 sec)
结果是
mysql> SELECT COUNT(*) FROM users WHERE username='joe' AND password=ENCRYPT('guessme', 'ab');
+----------+
| COUNT(*) |
+----------+
| 1 |
+----------+
1 row in set (0.00 sec)
提示:ENCRYPT()只能用在*NIX系统上,因为它需要用到底层的crypt()库。
幸运的是,上面的例子说明了能够如何利用MySQL对您的数据进行单向和双向的加密,并告诉了您一些关于如何保护数据库和其他敏感数据库信息安全的理念。
在PHP的开发中,虽然一直标榜LAMP是最佳搭配,但事实上,在小型项目中,sqlite的优势也很明显。pgsql和mysql也是处于同一竞争的水平线上。
sqlite小到一个文件就是一个表,象微软的access一样方便,而且从PHP5开始,就内置了对sqlite的支持(不过需要打开先PDO,才能支持,可以看我以前写的:为windows下面的PHP添加sqlite功能)
但很多人对于sqlite并不是很熟悉,正好在博客园看到有人介绍SQLITE,于是进行了很无耻的复制粘贴,一是笔记,二是传播。望原作者莫生气。
原文作者:arrowcat
原文链接:http://www.cnblogs.com/hustcat/archive/2009/02/12/1389448.html
原文如下:
写在前面:出于项目的需要,最近打算对SQLite的内核进行一个完整的剖析,在此希望和对SQLite有兴趣的一起交流。我知道,这是一个漫长的过程,就像曾经去读Linux内核一样,这个过程也将是辛苦的,但我相信结果一定是美好的... ...接下来是第一章。
1、SQLite介绍
自几十年前出现的商业应用程序以来,数据库就成为软件应用程序的主要组成部分。正与数据库管理系统非常关键一样,它们也变得非常庞大,并占用了相当多的系 统资源,增加了管理的复杂性。随着软件应用程序逐渐模块模块化,一种新型数据库会比大型复杂的传统数据库管理系统更适应。嵌入式数据库直接在应用程序进程 中运行,提供了零配置(zero-configuration)运行模式,并且资源占用非常少。
SQLite是一个开源的嵌入式关系数据库,它在2000年由D. Richard Hipp发布,它的减少应用程序管理数据的开销,SQLite可移植性好,很容易使用,很小,高效而且可靠。
SQLite嵌入到使用它的应用程序中,它们共用相同的进程空间,而不是单独的一个进程。从外部看,它并不像一个RDBMS,但在进程内部,它却是完整的,自包含的数据库引擎。
嵌入式数据库的一大好处就是在你的程序内部不需要网络配置,也不需要管理。因为客户端和服务器在同一进程空间运行。SQLite 的数据库权限只依赖于文件系统,没有用户帐户的概念。SQLite 有数据库级锁定,没有网络服务器。它需要的内存,其它开销很小,适合用于嵌入式设备。你需要做的仅仅是把它正确的编译到你的程序。
2、架构(architecture)
SQLite采用了模块的设计,它由三个子系统,包括8个独立的模块构成。
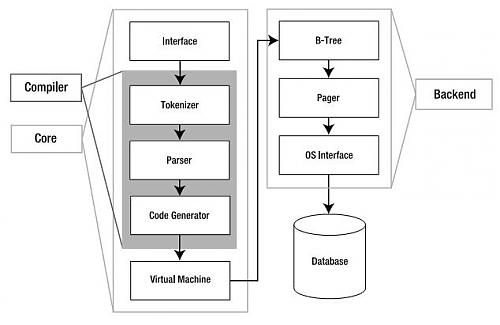
2.1、接口(Interface)
接口由SQLite C API组成,也就是说不管是程序、脚本语言还是库文件,最终都是通过它与SQLite交互的(我们通常用得较多的ODBC/JDBC最后也会转化为相应C API的调用)。
2.2、编译器(Compiler)
在编译器中,分词器(Tokenizer)和分析器(Parser)对SQL进行语法检查,然后把它转化为底层能更方便处理的分层的数据结构---语法 树,然后把语法树传给代码生成器(code generator)进行处理。而代码生成器根据它生成一种针对SQLite的汇编代码,最后由虚拟机(Virtual Machine)执行。
2.3、虚拟机(Virtual Machine)
架构中最核心的部分是虚拟机,或者叫做虚拟数据库引擎(Virtual Database Engine,VDBE)。它和Java虚拟机相似,解释执行字节代码。VDBE的字节代码由128个操作码(opcodes)构成,它们主要集中在数据 库操作。它的每一条指令都用来完成特定的数据库操作(比如打开一个表的游标)或者为这些操作栈空间的准备(比如压入参数)。总之,所有的这些指令都是为了 满足SQL命令的要求(关于VM,后面会做详细介绍)。
2.4、后端(Back-End)
后端由B-树(B-tree),页缓存(page cache,pager)和操作系统接口(即系统调用)构成。B-tree和page cache共同对数据进行管理。B-tree的主要功能就是索引,它维护着各个页面之间的复杂的关系,便于快速找到所需数据。而pager的主要作用就是 通过OS接口在B-tree和Disk之间传递页面。
3、SQLite的特点(SQLite’s Features and Philosophy)
3.1、零配置(Zero Configuration)
3.2、可移植(Portability):
它是运行在Windows,Linux,BSD,Mac OS X和一些商用Unix系统,比如Sun的Solaris,IBM的AIX,同样,它也可以工作在许多嵌入式操作系统下,比如QNX,VxWorks,Palm OS, Symbin和Windows CE。
3.3、Compactness:
SQLite是被设计成轻量级,自包含的。one header file, one library, and you’re relational, no external database server required
3.4、简单(Simplicity)
3.5、灵活(Flexibility)
3.6、可靠(Reliability):
SQLite的核心大约有3万行标准C代码,这些代码都是模块化的,很容易阅读。
主要参考:The Definitive Guide to SQLite

