Submitted by gouki on 2010, September 29, 10:19 PM
现在,懒得排版了。
遇到这个问题,从A表往B表导数据,初始SQL是这样的:
SQL代码
- REPLACE INTO shopnc_member_extend (member_id,sell_product_count)
- SELECT ug.uid,count(uid)
- FROM uchome_goods ug
- GROUP BY ug.uid
由于member_id不是主键,于是传说中的Replace删除数据的情况就出现了(replace在更新不是主键的时候,但某数据是唯一索引时,其实它是删除该数据,再insert,这时候如果你只是更新一两个字段,那么其余的字段就会变成默认值)。所以,该方法被我否决。但因为我只要更新一个字段,所以我想着用update,开始的时候,怎么也想不出,后来卫斯文和我说,用insert ignore into吧。于是把replace into 换成了 insert ignore into进行测试,结果是0 rows affected。
怎么办,问了一下锅巴哥哥,他说:用ON DUPLICATE KEY UPDATE吧,于是到mysql官方上找了一下资料,google搜索mysq on duplicate,第一条就是官方手册,我这里就不贴链接了,但我事实上没有看太懂。。这时候卫斯文也说用ON DUPLICATE KEY UPDATE。然后给了一个例子:
SQL代码
- INSERT INTO music_top_filtration (`sid`, `type`, `count_num`)
- SELECT sid,TYPE,count_num
- FROM music_top_version_day20100623 AS a
- LIMIT 1
- ON DUPLICATE KEY UPDATE music_top_filtration.count_num = music_top_filtration.count_num + VALUES(count_num)
虽然功能能不太一样,但已经有点差不多了,他对此sql的解释是:sid+type 为唯一索引,如果唯一索引重复则更新count_num字段。也就是说,我上面的例子其实是可以用这个insert into来实现的,因为member_id虽然不是主键,但它是唯一索引。
然后我就尝试着写update,写出了这样的语句:
SQL代码
- UPDATE shopnc_member_extend as sme , uchome_goods as ug SET sme.sell_product_count = (select count(*) from uchome_goods as uug where uug.uid=sme.member_id)
- WHERE sme.member_id=ug.uid;
执行下来,没问题,只是这个花费的时间啊,超多。。。正在思考的过程中,ThinkinLamp群中的newone又给了个例子,那就是用临时表,当时他写的SQL是这样的:
SQL代码
- update user set roleno=(select count(*) from user_has_roles where user_has_roles.member_id=user.member_id)
和我的SQL差不太多,然后他优化了一下,就成了这句(采用了临时表):
SQL代码
- update user a, (select count(*) as no,member_id from user_has_roles group by member_id) b set a.roleno=b.no where (a.member_id=b.member_id)
于是,参考newone写的sql,我最终的sql就成了:
SQL代码
- UPDATE shopnc_member_extend as sme ,( SELECT seller_id, count( * ) as cnt FROM `shopnc_product_sold` GROUP BY seller_id HAVING seller_id IS NOT NULL ) as tmp
- SET sme.sale_score = tmp.cnt
- WHERE sme.member_id = tmp.seller_id ;
执行了一下,速度刷刷的。只有0.x秒,oh yeah 。
其间,锅巴哥哥威胁我,要我参加他的mysql高级培训班,在此先鄙视一下。
DataBase | 评论:0
| 阅读:15725
Submitted by gouki on 2010, September 27, 9:48 PM
这两天在折腾数据,写了很多很多SQL(当然是对我来说,比如象锅巴那种牛人,他们一写就是几百上千行的,我不能比),我只写了100多行。基本上所有的操作都通过SQL完成了,除非实在没办法完成的。才用PHP处理。
对我来说,这两天 insert into xxx (xxx) select xxx from xxx where xxx,写的很多了
还有update a,b set a.xx=b.xx where a.id=b.id之类的也很多
在锅巴哥哥的介绍下,还知道把一句SQL分成多句,或者用下面这张图解决。。。
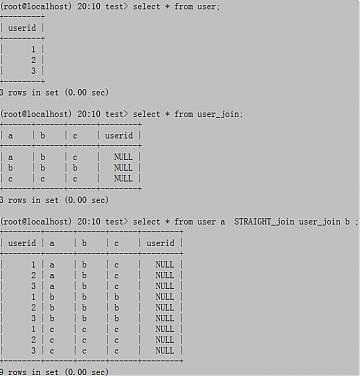
嗯,本来想用存储过程的,但赶时间,来不及学了。几年前看的东西全忘光了。靠,晚上回去翻开我的mysql书看一下下先。
Tags: mysql, sql
DataBase | 评论:0
| 阅读:16534
Submitted by gouki on 2010, September 9, 9:12 PM
新入职时,对于公司的业务不熟悉,这时候,你在干什么?看所谓的数据字典?熟悉老的程序?一行行的看代码?还是先熟悉一些程序员应该了解的后台操作?
虽然好象都应该这么做,但是在测试机上,你尝试性的做了一步操作,怎么查看他的结果?有多少数据表进行关联?除了看程序,还有没有其他办法 ?
下面就是一淘宝QA的技巧,值得推广。事实上,我是通过看程序了解的(看其中所涉及的SQL,但事实上,如果业务封装的很好,为了看这些所谓的SQL,可能需要查看很多程序文件,当然也可以通过debug模式,将这些受影响的SQL打印出来,这其实是最佳的。)
那么淘宝QA是怎么做的呢?他们不可能修改程序,否则就成了程序员而不是QA了。请看:
淘宝是一家业务驱动型的公司,想必每位小二都曾跟我一样,进来淘宝后,熟悉些基本的测试工具以后,就开始一头扎入茫茫的业务学习中去了。。。
每条线的业务都是错综复杂的,如何在千丝万缕中找到切入点,或许很多人曾经跟我一样迷茫,来吧,新人们可以踩着我的尸体上去了。好吧,为了纪念一下考级时候所用的英语模板,重新拿出来蹂躏一下,以作发泄。。。
当你做一个业务动作的时候,或许你最想知道的是,你的这个动作到底影响了哪几张表?OK,你有2个方法可以去寻找答案:问你的师兄师姐,看他们的沉淀、 tc,or自己去看数据库。这里,向后面的人推荐一下我个人比较笨拙的查数据库的方法,此方法只适用于清晨幽静无人之时:
一般,我会在清晨8点前来到公司,然后开始偷偷摸摸的干起来。
Firstly,把你所在线的表名都给导出来(找到数据库,在Tables下会显示这个库中的所有表,系统的表可以不用复制出来),如果是分表的话,看是 否是根据日期,user_id或是什么别的来分的,只要根据你操作的日期或者你的user_id等等来选择一张就行了;然后制作.sql的文件,内容如 下:
set heading off
set feedback off
spool d:\sb.sql(你的sql路径)
select count(*), ‘表名(刚才复制出来的)’ from 表名(刚才复制出来的) ;
(有多少表就写多少表,这个sql其实就是统计这个表现在有多少条记录)
spool off
set heading on
set feedback on
制作完成后,打开command window,输入刚才制作的.sql文件的路径:
我是保存在d盘下的
点击回车,就开始运行了,将你现在表中的记录数都打出来,
Started spooling to d:\sb.sql
14 xx_xxx_xxx ;
1 xx_xxx_xxx;
108 xx_xxx_xxx ;
Stopped spooling to d:\bss.sql
可以做一下ctrl+c,然后在ctrl+v,将这个东东保存在一个1.txt的文件中。
Secondly,开始你的业务操作,动作完成以后,再次输入.sql文件的路径,点回车,将新的记录数保存在另一个2.txt文件中。
Last but not least,你还需要一个工具来比较这2个文件,我用的是Beyond Compare,效果如下:
点击确定
你按照上面变红的数据表,对应数据字典去逐个看一下数据库中这些发生变化的表,你就明白你的这个操作为什么带来了这几张表的变化了。
欧拉。。。。。
原文来自:http://qa.taobao.com/?p=8804
Tags: 淘宝, 业务
DataBase | 评论:0
| 阅读:18053
Submitted by gouki on 2010, June 10, 9:11 AM
一直在用MYSQL,因此对于慢查询就非常在意,虽然自己写代码的时候不是特别注意,但真正上线后还是要关注关注的。
最简单的看LOG就是用phpmyadmin查看一下,但这终究不是办法。所幸,工具还是很多的。javaeye上就有人贴出了工具和使用方法 :
启用 slow log
有两种启用方式:
1, 在my.cnf 里 通过 log-slow-queries[=file_name]
2, 在mysqld进程启动时,指定--log-slow-queries[=file_name]选项
比较的五款常用工具
mysqldumpslow, mysqlsla, myprofi, mysql-explain-slow-log, mysqllogfilter
mysqldumpslow, mysql官方提供的慢查询日志分析工具. 输出图表如下:
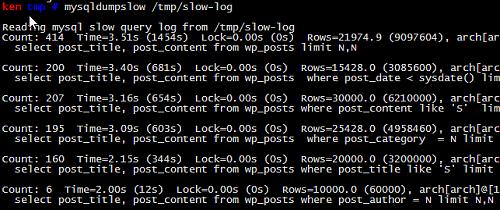
主要功能是, 统计不同慢sql的
出现次数(Count),
执行最长时间(Time),
累计总耗费时间(Time),
等待锁的时间(Lock),
发送给客户端的行总数(Rows),
扫描的行总数(Rows),
用户以及sql语句本身(抽象了一下格式, 比如 limit 1, 20 用 limit N,N 表示).
mysqlsla, hackmysql.com推出的一款日志分析工具(该网站还维护了 mysqlreport, mysqlidxchk 等比较实用的mysql工具)
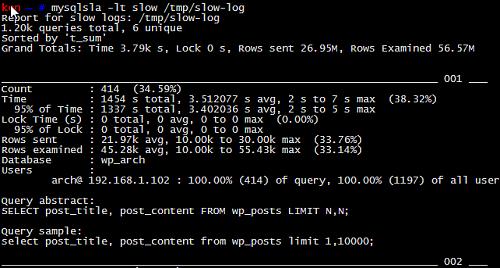
整体来说, 功能非常强大. 数据报表,非常有利于分析慢查询的原因, 包括执行频率, 数据量, 查询消耗等.
格式说明如下:
总查询次数 (queries total), 去重后的sql数量 (unique)
输出报表的内容排序(sorted by)
最重大的慢sql统计信息, 包括 平均执行时间, 等待锁时间, 结果行的总数, 扫描的行总数.
Count, sql的执行次数及占总的slow log数量的百分比.
Time, 执行时间, 包括总时间, 平均时间, 最小, 最大时间, 时间占到总慢sql时间的百分比.
95% of Time, 去除最快和最慢的sql, 覆盖率占95%的sql的执行时间.
Lock Time, 等待锁的时间.
95% of Lock , 95%的慢sql等待锁时间.
Rows sent, 结果行统计数量, 包括平均, 最小, 最大数量.
Rows examined, 扫描的行数量.
Database, 属于哪个数据库
Users, 哪个用户,IP, 占到所有用户执行的sql百分比
Query abstract, 抽象后的sql语句
Query sample, sql语句
除了以上的输出, 官方还提供了很多定制化参数, 是一款不可多得的好工具.
mysql-explain-slow-log, 德国人写的一个perl脚本.
http://www.willamowius.de/mysql-tools.html
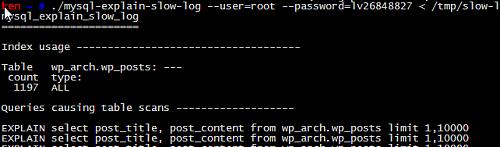
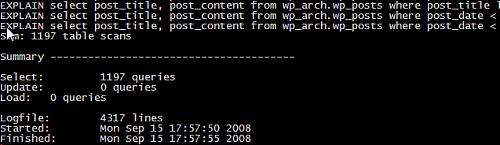
功能上有点瑕疵, 不仅把所有的 slow log 打印到屏幕上, 而且统计也只有数量而已. 不推荐使用.
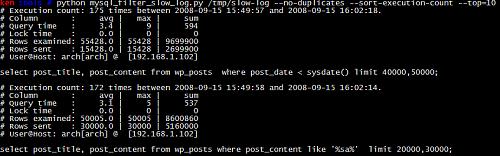
功能上比官方的mysqldumpslow, 多了查询时间的统计信息(平均,最大, 累计), 其他功能都与 mysqldumpslow类似.
特色功能除了统计信息外, 还针对输出内容做了排版和格式化, 保证整体输出的简洁. 喜欢简洁报表的朋友, 推荐使用一下.
myprofi, 纯php写的一个开源分析工具.项目在 sourceforge 上.
http://myprofi.sourceforge.net/
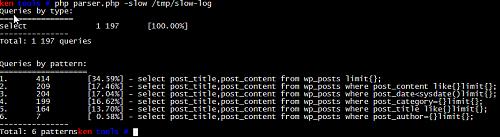
功能上, 列出了总的慢查询次数和类型, 去重后的sql语句, 执行次数及其占总的slow log数量的百分比.
从整体输出样式来看, 比mysql-log-filter还要简洁. 省去了很多不必要的内容. 对于只想看sql语句及执行次数的用户来说, 比较推荐.
总结
| 工具/功能 |
一般统计信息 |
高级统计信息 |
脚本 |
优势 |
| mysqldumpslow |
支持 |
不支持 |
perl |
mysql官方自带 |
| mysqlsla |
支持 |
支持 |
perl |
功能强大,数据报表齐全,定制化能力强. |
| mysql-explain-slow-log |
支持 |
不支持 |
perl |
无 |
| mysql-log-filter |
支持 |
部分支持 |
python or php |
不失功能的前提下,保持输出简洁 |
| myprofi |
支持 |
不支持 |
php |
非常精简 |
---EOF---
作者:galaxystar,来自:http://www.javaeye.com/topic/242516,他现在的博客是:http://kenwublog.com/。
Tags: slow query, mysql, tools
DataBase | 评论:0
| 阅读:21572
Submitted by gouki on 2010, May 25, 7:03 AM
很多人都使用过mysql命令行,不可否认的是在命令行下如果频繁切换use的database,你会感觉到很迷惘,不太清楚当前的库或表是哪个,于是发现这个技巧后就欣欣然的COPY下来与各位一起分享一下。
在my.cnf 的 mysql 端 添加如下设置
[mysql]
#no-auto-rehash # faster start of mysql but no tab completition
prompt="(\u:mysql1@linuxbyte.org \R:\m)[\d]: "
会产生如下效果:
root@ubuntu:/home/hew# mysql -u hew -p
Enter password:
Welcome to the MySQL monitor. Commands end with ; or \g.
Your MySQL connection id is 320
Server version: 5.1.41-3ubuntu12.1 (Ubuntu)
Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
(hew:mysql1@linuxbyte.org 21:12)[(none)]: use linuxbyte #注意这里
Database changed
(hew:mysql1@linuxbyte.org 21:13)[linuxbyte]: use linuxsky; #这里
Reading table information for completion of table and column names
You can turn off this feature to get a quicker startup with -A
Database changed
(hew:mysql1@linuxbyte.org 21:13)[linuxsky]: #这里
如上所示我们可以在mysql命令行下显示当前的mysql 用户,所在主机,时间和所用的数据库。
这个在关键时刻可以让我们避免很多误操作。
原文来自:http://www.blogread.cn/it/article.php?id=1605
Tags: mysql, 技巧
DataBase | 评论:0
| 阅读:18166

