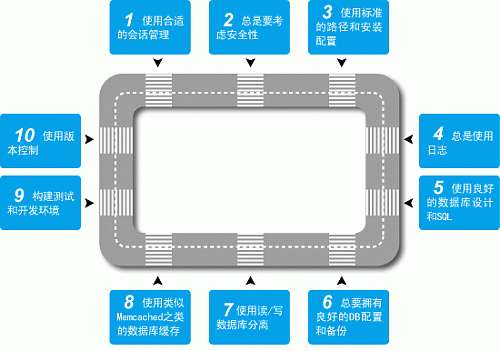
看到一篇文章,是这样说的:
use bitwish Operators "|" Convert a floating-point value to an int
意思就是:
由于位操作只对整型才有意义,所以表达式中的浮点数会首先被js解析器转换成整型.
然后再用js解析器本身的语言(例如:c++)的或操作将算 运符两边的数值运算,所以该例的结果得到整数1.
JavaScript代码
- alert(0|'123.55');
- alert(parseInt('123.55'));
- alert(Math.round('123.55'));
上面三种都可以转成int,但是math.round会四舍五入。
从名字可以看出来,这是向东的工作周报。不过,他的这一周,好长啊。。。其实是他每周的工作情况的简报啦。
这个习惯真好,我就没有养成。
他的第一个问题,我在以前与java那边交互的时候就遇到过,开始也是一直判断一直判断。最后发现获取的就是字符串,都跨语言了,还是用的curl来取值的,怎么可能传递布尔值?
最后它说的BOM问题,这就不太应该了。不过他的正则写得不错。我一直用editplus,文件选项里可是有一条:保存时始终去除BOM,就行了啦。用记事本,是会生成BOM的,微软的东西是差呀。。
框架这东西,仁者见仁智者见智,不多分析
原文如下:http://www.xiangdong.org/blog/post/1699/
近半年的工作心得,摘录如下:
( 2月 20 日-- 2月 26 日)
工作心得
一.Ajax通过POST提交给$_POST数组变量问题:
和 js人员一块调试ajax提交一些数据的时候,在ajax调用的时候,js人员通过Post方式传给我一个'allowComment',它为 True\false,刚开始误以为是一个TRUE 或 FALSE是PHP里面的一个布尔值(实际是一个字符串),于是写下如下代码片段:
if(true == $_POST['allowComment'])
{
$this->_par['allow_comment'] = 0;//0为允许评论
}else
{
$this->_par['allow_comment'] = 1;
}
导 致出现无论post过来的数据是true还是false,只走if不走else,当时很奇怪,我通过print_r()来打印看到明明是false,但是 还是不走else这条路,最后听建鑫说它是个字符串,我于是改用var_dump()函数来看:var_dump($_POST)发现它其实就是个 string类型的字符串:string(4) "ture",不是布尔型的一个变量。而修改为:(引号引起来即可)
if(‘true’ == $_POST['allowComment'])
{
$this->_par['allow_comment'] = 0;//0为允许评论
}else
{
$this->_par['allow_comment'] = 1;
}
结论:尽管PHP是弱类型语言,但我们调试时候最好用var_dump(),而不是print_r();
二.DIV模板取高度自动适应的问题:
在 做这次记录套页面的时候,提供的页面是一整张页面,这就需要php工程师去去掉里面的一些没有用的DIV标签和多余的html代码,但是在把最后剩下的一 些HTML代码套好页面后,在放到pengyou里面测试时候,发现页面被遮挡,最后发现是由于刘嵩Js想取到一个DIV的高度没有得到正确的值,而这正 是由于HTML设计人员把一整张页面让PHP开发人员去从里面提取出需要的东西,但是往往会出现某些DIV没有带到Smarty页面里渲染,才导致js在 通过ID或者NAME去取高度时候出错,也就是PHP工程师套页面的时候并不知道UI提供的页面中哪些DIV是JS人员必须要的,而UI人员就把整个页面 给PHP工程师自己去剔掉多余的DIV和HTML,而刚好把JS需要的DIV给干掉了造成的.
结论:切页面得按照产品结构来,而不是仅仅UE,涉及到JS的得事先和PHP工程师和JS人员沟通。
三.接口变动问题:
一 些底层接口的变动往往造成输入(入数据库)和输出(如:页面)出现一些明显的逻辑错误,于是我们首先会想可能是不是程序逻辑出现了问题,进一步去查程序代 码的逻辑是否严密,会发现数据库里面出现一些和现实逻辑不同的情况,而很容易把陈脚搞乱,特别是有其它系统的介入,更让人很难发现其中错误。
结论:尽量少动接口返回的数据结构,保持结口稳定,而一旦改变,及时通知接口使用和开发方。
( 3月 6 日-- 3月 12 日)
工作心得
对重构的一点体会:
1.改进软件的结构:
在开发记录的时候有时由于一个新的需求导致为了更快的满足用户,不故到程序的整体结构,而这种解决方法不能以一个系统的角度来解决问题,如果任其发展会使代码的质量越来越难以维护,而重构能改善这个问题。
2.增加可读性:
以 前的记录的数据层是由外包人员写的,让我觉得有点难懂,而有人说,修改别人的代码不如自己写,但事实上往往自己写的代码比上一个人还难以让别的人读懂,但 是如果这个人有一天离职或者没有上班那就有些耗费时间去读懂对方的代码,而我们的重构可以通过一些命名规范和类的规范和层次结构的规范来尽量防止这类事情 的发生,仅管我也参考了他们的代码。
3.及早地发现错误:
进行重构我们必须对项目的每一行代码的逻辑都了解,明确它的功能和上下程序调用关系,这样的理解我觉得有助于少犯错误和及时发现自己的错误。
4.提高了开发速度:
知道用户80%的需求的情况下,这种情况下重构,可能从一定程度上能提高开发速度。
( 3月 13 日-- 3月 19 日)
遇到一问题
在对记录的项目中进行重构的时候发现需要通过Ajax多提交一个POST变量到PHP那边去,发现不能随意加,而和js开发人员沟通了一下,结果是必须得 修改一下js代码,把多提交的一个加进去才行,但是我个人觉得js的Ajax Post应该做得像表单提交数据那样,只要多加一个数据<input type="text" value="add_value" name="XXX" id="XXX" />加入<form>
</form>表单,就可以对它POST提交到另一个PHP文件,而不是仅仅对一个单独的应用而写一个Ajax Post提交数据 ,不知能否改进成这样?
工作心得
1.
做项目最好先了解需求,然后明确需求,再思考用例,然后画数据流,最后才是数据库的设计,当然最后的数据库设计也是最重要的!
2.
对于一些定义分级和对应级别的少量数据最好放到PHP数组里面,而尽量不要放到数据库里,而对一些不是经常改动而却又是经常频繁查询用到的数据在量不是很在的情况下如放到数据库里面会显得成本太高,放到一个文本里变为一个配置文件来用效率可能会反而更高。
3.
对 大并发和高访问的数据库设计解决方法现目前还是分表,如还不行,再Hash打散分库,但不能无限分,一个库尽量256表,动用4个库来也就分了1000个 表左右,建鑫的经验告诉这样可能性能和稳定性相对高一些,而不能随意乱分。不知按时间或者天数来分表这种情况会有什么样的问题,期待通过人缘项目来尝试一 下。
2009-03-20 ----2009-03-26:
遇到一问题
工作心得
对于上次邮件里面讨论到的PHP BOM问题,我来说来句就当心得吧,其实这个BOM问题一直在我们进行开发的时候经常出现,前些日子在企业邮箱里面第一次遇到这个问题,当时好像是企业的图标LOGO没有办法显示出来,因为<img alt="" src="http://www.xiangdong.org/blog/img.php" />,是img.php去读一个图片的内容然后给img显示,经过长仔细排查出现在输出图片资源前就有输出,那时候用的是notepad+editplus,最后用Zend studio来看这个文件头出现一个锘�字,证明了该问题。
第二次遇到BOM问题,是陈鑫鑫在纸条项目里面输出XML数据到IE浏览器中展现出现XML错误。
第三次也就是我们的记录APP调用外部接口返回用户的昵称出现乱码,经琳琳查也由BOM造成!
为 何经常出现这种类似的问题,我看大家都在按照自己的方式来建立和开发PHP,特别是用Notepad来新建文件,系统默认在是ANSI格式,但我们的 PHP编码是UTF-8的,于是又通过Notepad的另存为修改为UTF-8格式的,这样也就产生了一个BOM,最后,再用现在统一的开发工具Zend for eclipse去编辑这个带BOM的PHP文件,但BOM依然存在文件当中,它一般是表现不出任何问题,但一旦在页面前不能有输出的情况:如上面我遇到的 三种情况它也就显现出来了。
BOM如此讨厌,该如何避免:
建议:
1. 切实统一开发工具:统一用Zend for eclipse 来新建PHP文件,和修改PHP文件编码!
2. 在 项目完成后对目录里面所有的PHP 文件进行遍历驱出有可能出现的BOM。如:用sed批量替换掉bom:(syscore目录和所有下级目录的PHP文件替换) find ./syscore -type f -name "*.php" -exec sed -i '1s/^\xef\xbb\xbf//' {} \;
(3月27日---4月2日)
遇到一问题:
在调试记录的js时发现超过了页数却没有出现翻页导航的页,开始首先以为是数据没有输出程序的问题, 最后查明是由于朋友下面的frame把下面给档住了,Js人员修正了这个问题,这个问题还经常出现,希望js人员也多注意一下!
工作心得:
本周收到老姜发的一点对PHP框架的看法,我也斗胆也说说我自己对这个问题的看法,有些可能说得不太准确或者有些错误,还望包含:
首先,我个人是不反对PHP采用一些轻量级的框架,但极力反对对PHP用一些重型的框架的,为什么呢?因为它的执行方式决定了它的这个特点:php每一 个脚本先全部载入所有资源,执行完毕后全部放弃,所以使用太重的框架,会极耗内存和计算资源,形成调用栈太深占用系统资源,个人觉得轻量框架和简单的分层 还是一定要采用的。
其次,你会说像Java这样的语言它能采用一些的框架,而且还涌现出了一些红红火火的框架了呢:)
个人觉得那是因 为java的执行方式和PHP不一样,对于内存管理也不一样,有很多都是一次装入内存,直到jvm重启才被释放的, 事务性,安全性等等很多基础性的服务,都需要预先装入,何况java是基于工业级应用产生的,php只是个人网站开发才出现的,能一样吗?不能。所以,不 能我们也不要一边倒,看人家采用什么什么了,自己也想把PHP往边上套。
再次,C++和Java强悍的框架不少,但惨不忍睹的框架也更多,为 什么呢?用一个越是尖端的东西越不容易用好,对于重型的编程语言对软件工程功底的要求是相当高的,不是谁说想做个框架就做个框架,更何况各个项目的千差万 别,实际的情况也不尽一样,更不能以一个框架来以逸待劳,放大了框架的作用,它并不是万能的。
最后,我仅对PHP的框架也就领悟到:轻量框架和简单的分层还是PHP在大多数项目开发中还是一定要采用的,但切忌过重,把握好度,适可而止。
转载这篇文章的原因是它解释了setTimeout和setInterval之间的区别,对于这篇文章,博客园有位朋友进行了翻译,网址如下:http://www.cnblogs.com/rainman/archive/2008/12/26/1363321.html
翻译内容为:
How JavaScript Timers Work
从基础的层面来讲,理解JavaScript的定时器是如何工作的是非常重要的。计时器的执行常常和我们的直观想象不同,那是因为JavaScript引擎是单线程的。我们先来认识一下下面三个函数是如何控制计时器的。
var id = setTimeout(fn, delay); - 初始化一个计时器,然后在指定的时间间隔后执行。该函数返回一个唯一的标志ID(Number类型),我们可以使用它来取消计时器。var id = setInterval(fn, delay); - 和setTimeout有些类似,但它是连续调用一个函数(时间间隔是delay参数)直到它被取消。clearInterval(id);, clearTimeout(id); - 使用计时器ID(setTimeout 和 setInterval的返回值)来取消计时器回调的发生
为了理解计时器的内在执行原理,有一个重要的概念需要加以探讨:计时器的延迟(delay)是无法得到保障的。由于所有JavaScript代码是在一个线程里执行的,所有异步事件(例如,鼠标点击和计时器)只有拥有执行机会时才会执行。用一个很好的图表加以说明:
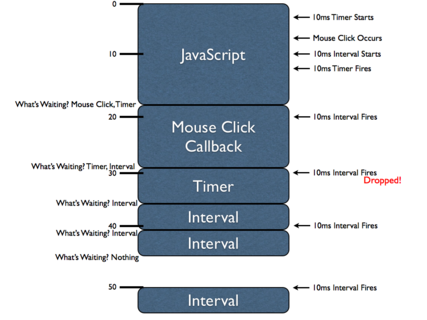
(点击查看大图)
在这个图表中有许多信息需要理解,如果完全理解了它们,你会对JavaScript引擎如何实现异步事件有一个很好的认识。这是一个一维的图标:垂 直方向表示时间,蓝色的区块表示JavaScript代码执行块。例如第一个JavaScript代码执行块需要大约18ms,鼠标点击所触发的代码执行 块需要11ms,等等。
由于JavaScript引擎同一时间只执行一条代码(这是由于JavaScript单线程的性质),所以每一个JavaScript代码执行块会 “阻塞”其它异步事件的执行。这就意味着当一个异步事件发生(例如,鼠标点击,计时器被触发,或者Ajax异步请求)后,这些事件的回调函数将排在执行队 列的最后等待执行(实际上,排队的方式根据浏览器的不同而不同,所以这里只是一个简化);
从第一个JavaScript执行块开始研究,在第一个执行块中两个计时器被初始化:一个10ms的setTimeout()和一个10ms的setInterval()。 依据何时何地计时器被初始化(计时器初始化完毕后就会开始计时),计时器实际上会在第一个代码块执行完毕前被触发。但是,计时器上绑定的函数不会立即执行 (不被立即执行的原因是JavaScript是单线程的)。实际上,被延迟的函数将依次排在执行队列的最后,等待下一次恰当的时间再执行。
此外,在第一个JavaScript执行块中我们看到了一个“鼠标点击”事件发生了。一个JavaScript回调函数绑定在这个异步事件上了(我 们从来不知道用户什么时候执行这个(点击)事件,因此认为它是异步的),这个函数不会被立即执行,和上面的计时器一样,它将排在执行队列的最后,等待下一 次恰当的时候执行。
当第一个JavaScript执行块执行完毕后,浏览器会立即问一个问题:哪个函数(语句)在等待被执行?在这时,一个“鼠标点击事件处理函数”和 一个“计时器回调函数”都在等待执行。浏览器会选择一个(实际上选择了“鼠标点击事件的处理函数”,因为由图可知它是先进队的)立即执行。而“计时器回调 函数”将等待下次适合的时间执行。
注意,当“鼠标点击事件处理函数”执行的时候,setInterval的回调函数第一次被触发了。和setTimeout的回调函数一样,它将排到执行队列的最后等待执行。但是,一定要注意这一点:当setInterval回调函数第二次被触发时(此时setTimeout函数仍在执行)setTimeout的第一次触发将被抛弃掉。当一个很长的代码块在执行时,可能把所有的setInterval回调函数都排在执行队列的后面,代码块执行完之后,结果便会是一大串的setInterval回调函数等待执行,并且这些函数之间没有间隔,直到全部完成。所以,浏览器倾向于的当没有更多interval的处理函数在排队时再将下一个处理函数排到队尾(这是由于间隔的问题)。
我们能够发现,当第三个setInterval回调函数被触发时,之前的setInterval回调函数仍在执行。这就说明了一个很重要的事实:setInterval不会考虑当前正在执行什么,而把所有的堵塞的函数排到队列尾部。这意味着两次setInterval回调函数之间的时间间隔会被牺牲掉(缩减)。
最后,当第二个setInterval回调函数执行完毕后,我们可以看到没有任何程序等待JavaScript引擎执行了。这就意味着浏览器现在在等待一个新的异步事件的发生。在50ms时一个新的setInterval回调函数再次被触发,这时,没有任何的执行块阻塞它的执行了。所以它会立刻被执行。
让我们用一个例子来阐明setTimeout和setInterval之间的区别:
setTimeout(function(){
/* Some long block of code... */
setTimeout(arguments.callee, 10);
}, 10);
setInterval(function(){
/* Some long block of code... */
}, 10);
这两句代码乍一看没什么差别,但是它们是不同的。setTimeout回调函数的执行和上一次执行之间的间隔至少有10ms(可能会更多,但不会少于10ms),而setInterval的回调函数将尝试每隔10ms执行一次,不论上次是否执行完毕。
在这里我们学到了很多知识,总结一下:
- JavaScript引擎是单线程的,强制所有的异步事件排队等待执行
setTimeout 和 setInterval 在执行异步代码的时候有着根本的不同- 如果一个计时器被阻塞而不能立即执行,它将延迟执行直到下一次可能执行的时间点才被执行(比期望的时间间隔要长些)
- 如果
setInterval回调函数的执行时间将足够长(比指定的时间间隔长),它们将连续执行并且彼此之间没有时间间隔。
上述这些知识点都是非常重要的。了解了JavaScript引擎是如何工作的,尤其是大量的异步事件(连续)发生时,才能为构建高级应用程序打好基础。
英文原文如下:
At a fundamental level it's important to understand how JavaScript timers work. Often times they behave unintuitively because of the single thread which they are in. Let's start by examining the three functions to which we have access that can construct and manipulate timers.
var id = setTimeout(fn, delay); - Initiates a single timer which will call the specified function after the delay. The function returns a unique ID with which the timer can be canceled at a later time.var id = setInterval(fn, delay); - Similar to setTimeout but continually calls the function (with a delay every time) until it is canceled.clearInterval(id);, clearTimeout(id); - Accepts a timer ID (returned by either of the aforementioned functions) and stops the timer callback from occurring.
In order to understand how the timers work internally there's one important concept that needs to be explored: timer delay is not guaranteed. Since all JavaScript in a browser executes on a single thread asynchronous events (such as mouse clicks and timers) are only run when there's been an opening in the execution. This is best demonstrated with a diagram, like in the following:
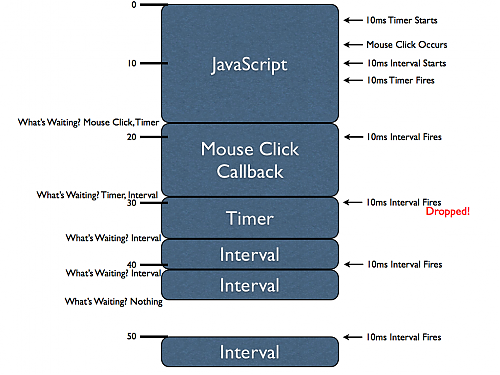
There's a lot of information in this figure to digest but understanding it completely will give you a better realization of how asynchronous JavaScript execution works. This diagram is one dimensional: vertically we have the (wall clock) time, in milliseconds. The blue boxes represent portions of JavaScript being executed. For example the first block of JavaScript executes for approximately 18ms, the mouse click block for approximately 11ms, and so on.
Since JavaScript can only ever execute one piece of code at a time (due to its single-threaded nature) each of these blocks of code are "blocking" the progress of other asynchronous events. This means that when an asynchronous event occurs (like a mouse click, a timer firing, or an XMLHttpRequest completing) it gets queued up to be executed later (how this queueing actually occurs surely varies from browser-to-browser, so consider this to be a simplification).
To start with, within the first block of JavaScript, two timers are initiated: a 10ms setTimeout and a 10ms setInterval. Due to where and when the timer was started it actually fires before we actually complete the first block of code. Note, however, that it does not execute immediately (it is incapable of doing that, because of the threading). Instead that delayed function is queued in order to be executed at the next available moment.
Additionally, within this first JavaScript block we see a mouse click occur. The JavaScript callbacks associated with this asynchronous event (we never know when a user may perform an action, thus it's consider to be asynchronous) are unable to be executed immediately thus, like the initial timer, it is queued to be executed later.
After the initial block of JavaScript finishes executing the browser immediately asks the question: What is waiting to be executed? In this case both a mouse click handler and a timer callback are waiting. The browser then picks one (the mouse click callback) and executes it immediately. The timer will wait until the next possible time, in order to execute.
Note that while mouse click handler is executing the first interval callback executes. As with the timer its handler is queued for later execution. However, note that when the interval is fired again (when the timer handler is executing) this time that handler execution is dropped. If you were to queue up all interval callbacks when a large block of code is executing the result would be a bunch of intervals executing with no delay between them, upon completion. Instead browsers tend to simply wait until no more interval handlers are queued (for the interval in question) before queuing more.
We can, in fact, see that this is the case when a third interval callback fires while the interval, itself, is executing. This shows us an important fact: Intervals don't care about what is currently executing, they will queue indiscriminately, even if it means that the time between callbacks will be sacrificed.
Finally, after the second interval callback is finished executing, we can see that there's nothing left for the JavaScript engine to execute. This means that the browser now waits for a new asynchronous event to occur. We get this at the 50ms mark when the interval fires again. This time, however, there is nothing blocking its execution, so it fires immediately.
Let's take a look at an example to better illustrate the differences between setTimeout and setInterval.
setTimeout(function(){
/* Some long block of code... */
setTimeout(arguments.callee, 10);
}, 10);
setInterval(function(){
/* Some long block of code... */
}, 10);
These two pieces of code may appear to be functionally equivalent, at first glance, but they are not. Notably the setTimeout code will always have at least a 10ms delay after the previous callback execution (it may end up being more, but never less) whereas the setInterval will attempt to execute a callback every 10ms regardless of when the last callback was executed.
There's a lot that we've learned here, let's recap:
- JavaScript engines only have a single thread, forcing asynchronous events to queue waiting for execution.
setTimeout and setInterval are fundamentally different in how they execute asynchronous code.- If a timer is blocked from immediately executing it will be delayed until the next possible point of execution (which will be longer than the desired delay).
- Intervals may execute back-to-back with no delay if they take long enough to execute (longer than the specified delay).
All of this is incredibly important knowledge to build off of. Knowing how a JavaScript engine works, especially with the large number of asynchronous events that typically occur, makes for a great foundation when building an advanced piece of application code.
(今天晚上要读书,所以先发上来)
昨天我们讲的是myisam表的特性,今天我们来讲讲innodb的一些特性。
之所以要采用innodb,是因为innodb有一些新的特性,而这些特性又是myisam所不具备的,它们是:事务、数据行级锁定、外键约束、崩溃恢复
看到上面这些特性,你是不是基本了解了innodb所应用的范围了?是的,innodb所具备的这些特性,使得mysql即使在高端应用也有了用武之地,特别是在处理类似银行这些对事务非常关心,也非常重要的场合(存钱取钱以及转帐等),下面就对这些特性进行简单介绍。
在介绍特性之间,先说明一下,innodb虽然一直是MSYQL的集成组件之一,但事实上,innodb的驱动的研发和收费技术支持都是来自innodb公司:http://www.innodb.com,这可是一家独立的公司。
事务:在innodb里所有的操作都可以被看成是在执行一个事务,它允许把几条有内在逻辑关系的SQL当成一个整体来执行。所以执行期间发生错误,则所有的命令会全部失效,就好象从未执行过任何SQL一样,而不仅仅是导致错误的那一条命令。正因为这样,所以事务功能相对增强了数据库的安全性。mysql支持全部的4种事务级别(READ UNCOMMITTED,READ COMMITED,REPEATABLE READ , SERIALIZABLE)
数据行级锁定:在执行事务时,innodb表的驱动程序会使用内置的行级锁定机制,而不是采用mysql自身的行级锁定机制。也就是说即使在执行事务时,其他进程仍然可以访问它,因为被锁定的仅仅是那些正在接收事务处理的记录。这与mysql的lock table不一样,lock table执行完后,整个表都被锁定了。这两种方式的对比可以让你看出,如果有一大堆人在处理一个很大的数据表,孰优孰劣一看便知。并且,innodb的这个驱动相对比较先进的就是,它能够自动识别“死锁”(所谓死锁,就是两个进程各战胜一项对方需要的资源,同时又在等待对方先释放所占用的资源,结果导致两个进程都不能执行),并自动终止两个进程中的一个。这才是innodb的强项。
外键约束:如果在数据表间定义了关联,innodb驱动将自动保证数据表的引用一致性,即便在执行过delete后也能同样保持。也就是说,不可能出现在A表的记录引用B表一条并不存在的记录,这就是所谓的:外键约束
崩溃恢复:理论上,在数据库发生崩溃后,只要计算机的文件系统没有被破坏,innodb数据表能够迅速地自动恢复到一个稳定可用的状态。说明一下,这只是理论上,具体怎么样,我没有测试过,也没有搜索到相关文章,如果有人搜索到相关的资料,请告知,以便我更新一下,谢谢。
说了这么多的特性,下面也要谈谈它的缺点,毕竟凡事都有双面性,有优点自然也会存在缺点,否则,谁还会用myisam?
使用innodb有以下几个缺点:
1、表空间的管理。与myisam分成三个文件的存储方式不一样,innodb把所有的数据、索引、结构都存在了一个表空间里。当然,表空间可以是一个或多个文件组成,也就是说这些文件组成了一个虚拟的文件系统。然而问题就出在这里,这些文件被创建后只能增长,不能缩小。如果想复制innodb表,只有使用mysqldump来进行处理,而myisam在停掉数据库后,直接复制就可以了(好象到了4.1或5.0后,这样的直接复制好象不行了?我是指两个表的设置如果不一样的话)
2、数据记录的长度。innodb的单条记录最多占用8000个字节。这个限制不包括text和blob等类型字段,事实上,这此字段只有前512个字节和其他数据存在数据库里,超过这个长度的内容都是被存储在上面所说的“虚拟文件系统——表空间”的其他文件里面。在这里,有一个回复,也可以参考一下,虽然不一定完全正确:http://imysql.cn/node/548,呵呵。
3、存储空间。在内容相同的情况下,一般来说innodb所占用的空间要比myisam所占用的大的多,最多时,可能会有两倍。
4、全文索引。这恐怕是它最大的缺憾了,innodb不支持full-text index。
5、GIS数据。存储和读取这个,还是myisam来的更方便一点,所以innodb也不支持它。
6、COUNT相关。innodb在处理SELECT COUNT(*) FROM table的时候,比myisam慢得多,这主要是因为它支持事务。可是,我在用sql server的时候也没有慢很多嘛。不知道它何时能够被解决,否则在内容较大的时候,处理分页就烦了。
7、表锁定。因为innodb有自己的表锁定算法,所以想使用表锁定功能时,用innodb所支持的select .. for update或select .. IN share mode,而不要使用mysql 自带的lock table。
8、虽然有这么多好处,可惜mysql这张表,还是得用myisam格式。而不能使用innodb
9、费用。。。。对于我们个人来说,我们只需要使用免费的mysql,而不是使用商业版的mysql,那么收费就与我们无缘了。至于商业应用嘛,那,钱是少不了的,听说,如果在mysql许可证里加上innodb支持,将收取双倍费用。好恐怖。。。
上面的这些也是我在参考书本后,进行的整理,否则,凭我这些小小的经验,怎么可能了解这么多?
目的:
对目前已有的 Web 应用系统,和将来待开发的 Web 应用系统进行集成,实现单点登录。
要求:
- 对已有的 Web 应用系统不作大规模改造。
- 不限制待开发的 Web 应用系统的开发工具。
- 不增加待开发系统的开发难度。
分析:
- 目前,已有的系统都各自维护自己的一套用户库,每个系统中的用户数、用户名、密码几乎都各不相同。要将已有的用户库进行统一是不现实的。因此,我们可以通过将单点登录系统中的用户与其它个系统中的用户建立映射,来实现用一个帐号来管理多个系统的目的。
- 已 有的 Web 应用系统、以及待开发的 Web 应用系统,可能不在同一个域下,虽然会话本身是保存在服务器端,但是会话 id 是需要 cookie 来传递的,而 cookie 不允许跨域访问,而且考虑到各个系统的开发工具也各不相同,即使在同一个域下,不同的开发工具所开发的应用程序之间也很难共享会话,因此要用共享会话的方 式来实现单点登录也不现实。因此我们通过在客户端浏览器、单点登录系统和 Web 应用系统之间传递临时会话,并让 Web 应用系统直接到单点登录系统中获取认证信息来实现单点登录。为保证不同开发工具都能够到单点登录系统获取认证信息,我们采用 xml-rpc 在 Web 应用系统和单点登录系统之间进行通讯。
实现:
单点登录系统中设置 4 个表:
- 单点登录系统用户表,包含 user_id,name,password 3 个字段。
- Web 应用系统表,包含 app_id,name(Web 应用系统名称),checkurl(Web 应用系统中用来验证用户登录的程序地址) 3 个字段。
- 单点登录系统用户到各个 Web 应用系统的用户映射表,包含id,user_id,app_id,name,password 5 个字段。
- 临时会话表,包含 hash(临时会话的 hash 编号),id(对应单点登录系统用户到各个 Web 应用系统的用户映射表中的 id 字段) 2个字段。
用户登录单点登录系统时,通过单点登录系统用户表中的字段来验证用户身份。登录以后,用户可以设置各个系统到该系统用户的映射关系。设置好以后,当通过该 系统进入其他某个 Web 应用系统时,该系统会为该用户和该系统生成一个临时会话编号(hash),并转到 Web 应用系统中的登录检测页面,登录检测页面通过获取到的临时会话编号,来调用单点登录系统的获取用户名和密码的 xml-rpc API,如果用户名密码如果正确,则转到正常登录后的页面,如果不正确,则转到登录错误的页面。这里,xml-rpc API 在返回用户名和密码后,将删除单点登录系统数据库中相应的临时会话,这样不但用户名、密码都是在服务器之间进行传递的,并且临时会话存在的时间也是尽可能 的短,因此只要保证服务器之间的对话不能被监听,即可保证安全性。 已有系统需要增加一个用于单点登录系统的登录验证页面,该页面工作过程大致如下:
- 获取 客户端 hash 值
- 通过 hash 值得到用户名和密码(xml-rpc 调用)
- 通过用户名和密码进行身份验证
- 返回身份验证后的页面
原作者:andot,来源coolcode.cn,原文:http://www.coolcode.cn/show-89-1.html