不多说了上图。。。顺便提一问,我的某PDF100多M的打不开,真痛苦。。。60多M的可以开,只是很慢。100多M的直接白屏。伤心啊,还是只能看小文件的PDF了。
开始上图吧。。【本来是想买yoobao的,但卖家说人家是做电池的不是做外包装的。于是换 了这个。当然我也知道可能这个利润更高一点。无所谓了,大家都开心就好。我看的舒服也就好了。。。】

包装盒

外包装

张开双翼

台式书
Submitted by gouki on 2010, June 27, 1:15 PM
不多说了上图。。。顺便提一问,我的某PDF100多M的打不开,真痛苦。。。60多M的可以开,只是很慢。100多M的直接白屏。伤心啊,还是只能看小文件的PDF了。
开始上图吧。。【本来是想买yoobao的,但卖家说人家是做电池的不是做外包装的。于是换 了这个。当然我也知道可能这个利润更高一点。无所谓了,大家都开心就好。我看的舒服也就好了。。。】
包装盒
外包装
张开双翼
台式书
Submitted by gouki on 2010, June 27, 8:30 AM
让人意外的是这个标题:【Google爬虫:不仅索引链接,还可以运行js代码】,真的没想过,看看cnbeta怎么说的?
一直以来Google的搜索爬虫就具有阅读JavaScript代码的功能,但是多年以来我们一直都不清楚Google的爬虫是否真正理解了其正在抓取的 东西或者说它仅仅只是在易于理解的数据结构中对各种链接进行呆板的检索。本周五,一位Google的发言人向《福布斯》确认Google所作的远远超过对 js代码的简单分析。这位发言人表示:“Google能够分析并理解某些JavaScript”。
Google的表述让我们意识到其爬虫所作的工作也许不仅仅只是获得对页面的相关链接,还能够像人一样与各类程序发生互动——发现Bing这类搜索引擎所 不能发现的网络世界。而这意味着,Google重新定义了搜索引擎。在Google的搜索结果里面只有很少的js代码,而且Google也将这种js代码 的解释功能做了很多保留。比如在Google站点搜索(Google's Site Search)的文档显示其不能够索引带有js代码的内容。一本关于索引的入门教材这样写道:它(Google爬虫)“不能够处理带有富媒体的内容或者是 动态网页”。仔细检查服务器日志中的记录我们便可以发现Google现在索引那些并不是直接包含在js代码里面的链接,Google的爬虫只有确定自己能够运行部分代码的时候才能明白整段代码到底是什么意思。
Mark Drummond,一家独立搜索引擎公司Wowd的首席执行官(我们在今年之前的杂志中采访过他)在一封邮件中告诉我们理解js代码“是一个非常深刻、难度极大和一场经典的计算科学难题。”他解释道Google的努力在于它能够发现js代码在网页中是否存在停止运行的情况。 他表示“停止运行的问题是无法判定的”,他说迄今为止还没有已知的算法能够在任何程序的任何时间点告诉我们该程序是否陷入了死循环,而且数学上已经证明了 这一点。Drummond自己的公司通过人工的方式检索其索引并标明是否有可能简化这个复杂的问题,同时判断一个网络程序是否向另外的程序发起了数据请 求。也许,这正是Google现在在做的事情。
另一位同Google接近的搜索引擎人士也认同Drummond关于理解js代码复杂性的看法。他认为用一个程序去分析另一个程序是很困难的事情,执行js代码几乎是现阶段能够做到的极限了。
而Google在六月发布的改进版搜索算法(即Caffeine)似乎开始能够理解部分js代码了。如果这是真的,那么Google的工程师已经教会了其爬虫如何执行部分js代码。这真是一大突破!
cnBeta.com编译自Forbes
--EOF--
额。这样就比较有意思了。。JS也能够被解析?确实有点恐怖,未来会怎么样?真的是象浏览器一样的访问吗?他们也会兼容所有的浏览器吗?会。。。模拟登录吗?这才是我关心的,会识别验证码吗?
Submitted by gouki on 2010, June 27, 7:37 AM
一般来说,限速这东西仅限于FTP,可以给FTP用户进行限速,但,如果你没有FTP,仅有HTTP的情况下如何呢?上次vampire演示过一段,同时还根据URL来读取文件的区块。事实上我们的需要没有那么复杂,向tom zheng博客上的这段就够我们用了。不是吗?再者,现在用nginx的机器应该很多了吧(我没有用,因为,我不可能为线上每个用户都去设置一遍他们的rewrite规则。只能将就一下了。)
原文来自:http://zys.8800.org/index.php/archives/322
nginx可以通过HTTPLimitZoneModule和HTTPCoreModule两个目录来限速。
示例:
limit_zone one $binary_remote_addr 10m;
location / {
limit_conn one 1;
limit_rate 100k;
}
说明:
limit_zone,是针对每个IP定义一个存储session状态的容器。这个示例中定义了一个10m的容器,按照32bytes/session,可以处理320000个session。
然后针对 /目录进行设定。
limit_conn one 1; 是限制每个IP只能发起一个连接。
limit_rate 100k; 是对每个连接限速100k. 注意,这里是对连接限速,而不是对IP限速。如果一个IP允许两个并发连接,那么这个IP就是限速limit_rate x 2。
关于limit_zone的原始文档,请见 http://wiki.nginx.org/NginxHttpLimitZoneModule
关于limit_rate和limit_conn的原始文档,请见 http://wiki.nginx.org/NginxHttpCoreModule
Submitted by gouki on 2010, June 27, 7:30 AM
Facebook 的照片分享很受欢迎,迄今,Facebook 用户已经上传了150亿张照片,加上缩略图,总容量超过1.5PB,而每周新增的照片为2亿2000万张,约25TB,高峰期,Facebook 每秒处理55万张照片,这些数字让如何管理这些数据成为一个巨大的挑战。本文由 Facebook 工程师撰写,讲述了他们是如何管理这些照片的。
旧的 NFS 照片架构
老的照片系统架构分以下几个层:
# 上传层接收用户上传的照片并保存在 NFS 存储层。
# 照片服务层接收 HTTP 请求并从 NFS 存储层输出照片。
# NFS存储层建立在商业存储系统之上。
因为每张照片都以文件形式单独存储,这样庞大的照片量导致非常庞大的元数据规模,超过了 NFS 存储层的缓存上限,导致每次招聘请求会上传都包含多次I/O操作。庞大的元数据成为整个照片架构的瓶颈。这就是为什么 Facebook 主要依赖 CDN 的原因。为了解决这些问题,他们做了两项优化:
# Cachr: 一个缓存服务器,缓存 Facebook 的小尺寸用户资料照片。
# NFS文件句柄缓存:部署在照片输出层,以降低 NFS 存储层的元数据开销。
新的 Haystack 照片架构
新的照片架构将输出层和存储层合并为一个物理层,建立在一个基于 HTTP 的照片服务器上,照片存储在一个叫做 haystack 的对象库,以消除照片读取操作中不必要的元数据开销。新架构中,I/O 操作只针对真正的照片数据(而不是文件系统元数据)。haystack 可以细分为以下几个功能层:
# HTTP 服务器
# 照片存储
# Haystack 对象存储
# 文件系统
# 存储空间
存储
Haystack 部署在商业存储刀片服务器上,典型配置为一个2U的服务器,包含:
# 两个4核CPU
# 16GB – 32GB 内存
# 硬件 RAID,含256-512M NVRAM 高速缓存
# 超过12个1TB SATA 硬盘
每个刀片服务器提供大约10TB的存储能力,使用了硬件 RAID-6, RAID 6在保持低成本的基础上实现了很好的性能和冗余。不佳的写性能可以通过高速缓存解决,硬盘缓存被禁用以防止断电损失。
文件系统
Haystack 对象库是建立在10TB容量的单一文件系统之上。文件系统中的每个文件都在一张区块表中对应具体的物理位置,目前使用的文件系统为 XFS。
Haystack 对象库
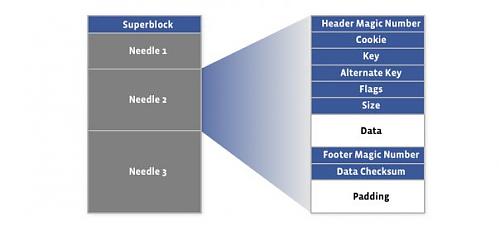
Haystack 是一个简单的日志结构,存储着其内部数据对象的指针。一个 Haystack 包括两个文件,包括指针和索引文件:
Haystack 对象存储结构


指针和索引文件结构
Haystack 写操作
Haystack 写操作同步将指针追加到 haystack 存储文件,当指针积累到一定程度,就会生成索引写到索引文件。为了降低硬件故障带来的损失,索引文件还会定期写道存储空间中。
Haystack 读操作
传到 haystack 读操作的参数包括指针的偏移量,key,代用Key,Cookie 以及数据尺寸。Haystack 于是根据数据尺寸从文件中读取整个指针。
Haystack 删除操作
删除比较简单,只是在 Haystack 存储的指针上设置一个已删除标志。已经删除的指针和索引的空间并不回收。
照片存储服务器
照片存储服务器负责接受 HTTP 请求,并转换成相应的 Haystack 操作。为了降低I/O操作,该服务器维护着全部 Haystack 中文件索引的缓存。服务器启动时,系统就会将这些索引读到缓存中。由于每个节点都有数百万张照片,必须保证索引的容量不会超过服务器的物理内存。
对于用户上传的图片,系统分配一个64位的独立ID,照片接着被缩放成4种不同尺寸,每种尺寸的图拥有相同的随机 Cookie 和 ID,图片尺寸描述(大,中,小,缩略图)被存在代用key 中。接着上传服务器通知照片存储服务器将这些资料联通图片存储到 haystack 中。
每张图片的索引缓存包含以下数据

Haystack 使用 Google 的开源 sparse hash data 结构以保证内存中的索引缓存尽可能小。
照片存储的写/修改操作
写操作将照片数据写到 Haystack 存储并更新内存中的索引。如果索引中已经包含相同的 Key,说明是修改操作。
照片存储的读操作
传递到 Haystack 的参数包括 Haystack ID,照片的 Key, 尺寸以及 Cookie,服务器从缓存中查找并到 Haystack 中读取真正的数据。
照片存储的删除操作
通知 Haystack 执行删除操作之后,内存中的索引缓存会被更新,将便宜量设置为0,表示照片已被删除。
重新捆扎
重新捆扎会复制并建立新的 Haystack,期间,略过那些已经删除的照片的数据,并重新建立内存中的索引缓存。
HTTP 服务器
Http 框架使用的是简单的 evhttp 服务器。使用多线程,每个线程都可以单独处理一个 HTTP 请求。
结束语
Haystack 是一个基于 HTTP 的对象存储,包含指向实体数据的指针,该架构消除了文件系统元数据的开销,并实现将全部索引直接存储到缓存,以最小的 I/O 操作实现对照片的存储和读取。
本文国际来源:http://www.facebook.com/FacebookEngineering#/note.php?note_id=76191543919&ref=mf
中文翻译来源:COMSHARP CMS 官方网站
我的来源:http://zys.8800.org/index.php/archives/334
| « 2010年06月 » | ||||||
| 日 | 一 | 二 | 三 | 四 | 五 | 六 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 | |||
 [641] [9] [38] [14] [2] [10] [298] [64] [277] [224] [161] [234] [9] [22] [12] [960] [92]
[641] [9] [38] [14] [2] [10] [298] [64] [277] [224] [161] [234] [9] [22] [12] [960] [92]