昨天晚上asers.z问我怎么样使得数据在搜索的时候和58.com差不多,而且展示数据的速度要快。我一直想着用mysql的分区表解决,而乔楚(乔 大姐)则认为是采用sphinx来解决。
但后来我找了一个资料才发现,原来分区表还是有局限性的,比如他就不支持全文索引。我是看这里看到的。。
» 阅读全文

 膘叔的简单人生 , 腾讯云RDS购买 | 超便宜的Vultr , 免费部署 N8N 的 Zeabur
注册 | 登陆
膘叔的简单人生 , 腾讯云RDS购买 | 超便宜的Vultr , 免费部署 N8N 的 Zeabur
注册 | 登陆
Submitted by gouki on 2010, March 18, 8:59 AM
昨天晚上asers.z问我怎么样使得数据在搜索的时候和58.com差不多,而且展示数据的速度要快。我一直想着用mysql的分区表解决,而乔楚(乔 大姐)则认为是采用sphinx来解决。
但后来我找了一个资料才发现,原来分区表还是有局限性的,比如他就不支持全文索引。我是看这里看到的。。
» 阅读全文
Submitted by gouki on 2010, January 4, 9:08 PM
关于使用GUID和INT做主键,性能差异的文章历来很多,不过。大多都是从理论上来说明,这次难得看到某人用PC机做测试,所以贴上来看看。但我不贴全文,毕竟。。。大量的代码贴上来,也没有太大的意义 。所以仅贴上主体内容和测试结果,当然还会有一些用户的评论。。
原文网址为:http://www.cnblogs.com/jackhuclan/archive/2010/01/04/1639005.html
内容大致如下,【如想看全文,请使用上面的链接】
在数据库的设计中我们常常用Guid或int来做主键,根据所学的知识一直感觉int做主键效率要高,但没有做仔细的测试无法说明道理。碰巧今天在数据库的优化过程中,遇到此问题,于是做了一下测试。
测试环境:
台式电脑 Pentiun(R) 4 Cpu 3.06GHz
Win XP professional
1.5G DDR RAM
SQL Server 2005 个人版
测试过程:
首先创建测试数据库Test
1.创建Test_Guid表,创建Test_Int表
2.创建Test_Guid子表:Test_Guid_Detail和创建Test_Int子表:Test_Int_Detail,用来做连接查询
3、然后进行一些CRUD的操作【这是我写的,因为原文中写插入N行数据,删除N行数据之类的太复杂,也太多,简化为一句话了】
测试结果如下:
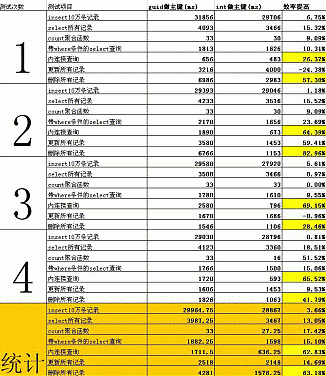
综上所述,使用int做主键比用guid做主键各中情况下效率均有提高,特别是在有连接查询和删除记录效率提升明显。
而且本人今日在guid做主键的数据查询中因为嵌套几个子查询结果屡屡出现查询超时。因此本人赞同用int做主键,不赞同guid做主键。
以上观点代表个人观点,欢迎大家各抒己见,说明guid和int各自做主键的优劣所在。
----EOF---
本来到这里就可以结束了,但有一个用户的评论还算不错:
更多的人认为GUID在做数据迁移的时候很方便,而如果使用INT则会有意料不到的问题。而GUID遇到的问题会少很多。。。
相对于以上的观点我还是比较认同的,但我认为性能相差这么大是有可能有以下的原因:
1、作者用的是PC机
2、操作系统是XP
3、sql server 是个人版【我没有试用服务器版性能如何,但我想,一定比个人版性能更优,当然这是猜测】
说归说,对于MYSQL来说,基本上还是只能使用INT做主键。毕竟MYSQL没有自带的生成GUID的方法【我不是指手动生成,我是说自动生成。。。UUID()函数是可以生成GUID的,但不能象INT那样自动插入,也没有办法设置default为UUID()方法】
Submitted by gouki on 2010, January 3, 1:21 PM
MYISAM和INNODB的争论由来已久,如今,我又找到两篇文章,让我们看看有关这两种引擎的优劣的文章:浅谈MySQL存储引擎选择 InnoDB还是MyISAM以及InnoDB还是MyISAM 再谈MySQL存储引擎的选择
第一篇:浅谈MySQL存储引擎选择 InnoDB还是MyISAM
作者:酷壳,来源于:http://database.51cto.com/art/200905/122382.htm
MyISAM 是MySQL中默认的存储引擎,一般来说不是有太多人关心这个东西。决定使用什么样的存储引擎是一个很tricky的事情,但是还是值我们去研究一下,这里的文章只考虑 MyISAM 和InnoDB这两个,因为这两个是最常见的。
下面先让我们回答一些问题:
◆你的数据库有外键吗?
◆你需要事务支持吗?
◆你需要全文索引吗?
◆你经常使用什么样的查询模式?
◆你的数据有多大?
思考上面这些问题可以让你找到合适的方向,但那并不是绝对的。如果你需要事务处理或是外键,那么InnoDB 可能是比较好的方式。如果你需要全文索引,那么通常来说 MyISAM是好的选择,因为这是系统内建的,然而,我们其实并不会经常地去测试两百万行记录。所以,就算是慢一点,我们可以通过使用Sphinx从 InnoDB中获得全文索引。
数据的大小,是一个影响你选择什么样存储引擎的重要因素,大尺寸的数据集趋向于选择InnoDB方式,因为其支持事务处理和故障恢复。数据库的在小 决定了故障恢复的时间长短,InnoDB可以利用事务日志进行数据恢复,这会比较快。而MyISAM可能会需要几个小时甚至几天来干这些事,InnoDB 只需要几分钟。
您操作数据库表的习惯可能也会是一个对性能影响很大的因素。比如: COUNT() 在 MyISAM 表中会非常快,而在InnoDB 表下可能会很痛苦。而主键查询则在InnoDB下会相当相当的快,但需要小心的是如果我们的主键太长了也会导致性能问题。大批的inserts 语句在MyISAM下会快一些,但是updates 在InnoDB 下会更快一些——尤其在并发量大的时候。
所以,到底你检使用哪一个呢?根据经验来看,如果是一些小型的应用或项目,那么MyISAM 也许会更适合。当然,在大型的环境下使用MyISAM 也会有很大成功的时候,但却不总是这样的。如果你正在计划使用一个超大数据量的项目,而且需要事务处理或外键支持,那么你真的应该直接使用InnoDB方 式。但需要记住InnoDB 的表需要更多的内存和存储,转换100GB 的MyISAM 表到InnoDB 表可能会让你有非常坏的体验。
第二篇:InnoDB还是MyISAM 再谈MySQL存储引擎的选择
作者:邵宗文,来源于:http://database.51cto.com/art/200905/124370.htm
两种类型最主要的差别就是Innodb 支持事务处理与外键和行级锁.而MyISAM不支持.所以MyISAM往往就容易被人认为只适合在小项目中使用。
我作为使用MySQL的用户角度出发,Innodb和MyISAM都是比较喜欢的,但是从我目前运维的数据库平台要达到需求:99.9%的稳定性,方便的扩展性和高可用性来说的话,MyISAM绝对是我的首选。
原因如下:
1、首先我目前平台上承载的大部分项目是读多写少的项目,而MyISAM的读性能是比Innodb强不少的。
2、MyISAM的索引和数据是分开的,并且索引是有压缩的,内存使用率就对应提高了不少。能加载更多索引,而Innodb是索引和数据是紧密捆绑的,没有使用压缩从而会造成Innodb比MyISAM体积庞大不小。
3、从平台角度来说,经常隔1,2个月就会发生应用开发人员不小心update一个表where写的范围不对,导致这个表没法正常用了,这个时候 MyISAM的优越性就体现出来了,随便从当天拷贝的压缩包取出对应表的文件,随便放到一个数据库目录下,然后dump成sql再导回到主库,并把对应的 binlog补上。如果是Innodb,恐怕不可能有这么快速度,别和我说让Innodb定期用导出xxx.sql机制备份,因为我平台上最小的一个数据 库实例的数据量基本都是几十G大小。
4、从我接触的应用逻辑来说,select count(*) 和order by 是最频繁的,大概能占了整个sql总语句的60%以上的操作,而这种操作Innodb其实也是会锁表的,很多人以为Innodb是行级锁,那个只是 where对它主键是有效,非主键的都会锁全表的。
5、还有就是经常有很多应用部门需要我给他们定期某些表的数据,MyISAM的话很方便,只要发给他们对应那表的frm.MYD,MYI的文件,让 他们自己在对应版本的数据库启动就行,而Innodb就需要导出xxx.sql了,因为光给别人文件,受字典数据文件的影响,对方是无法使用的。
6、如果和MyISAM比insert写操作的话,Innodb还达不到MyISAM的写性能,如果是针对基于索引的update操作,虽然MyISAM可能会逊色Innodb,但是那么高并发的写,从库能否追的上也是一个问题,还不如通过多实例分库分表架构来解决。
7、如果是用MyISAM的话,merge引擎可以大大加快应用部门的开发速度,他们只要对这个merge表做一些select count(*)操作,非常适合大项目总量约几亿的rows某一类型(如日志,调查统计)的业务表。
当然Innodb也不是绝对不用,用事务的项目如模拟炒股项目,我就是用Innodb的,活跃用户20多万时候,也是很轻松应付了,因此我个人也是很喜欢Innodb的,只是如果从数据库平台应用出发,我还是会首选MyISAM。
另外,可能有人会说你MyISAM无法抗太多写操作,但是我可以通过架构来弥补,说个我现有用的数据库平台容量:主从数据总量在几百T以上,每天十 多亿 pv的动态页面,还有几个大项目是通过数据接口方式调用未算进pv总数,(其中包括一个大项目因为初期memcached没部署,导致单台数据库每天处理 9千万的查询)。而我的整体数据库服务器平均负载都在0.5-1左右。
文章都不太长,适合着看看就行了。。
Submitted by gouki on 2009, December 25, 9:45 AM
本以为自己用不上这类东西,因为自己的密码几乎都记得。然而经验是没有用的。我确实就忘记了密码。还好有google。找到了这篇:
可惜,在linux下好象不太正确。当然或许我用的是ubuntu的关系。。
找了一下,找不到safe_mysqld,于是我进入/etc/init.d/目录,打开mysql文件,查看了一下里面安全启动的文件发现居然是mysqld_safe。郁闷了一下。。。
作个笔记。
Submitted by gouki on 2009, December 10, 12:35 PM
正如本文的最后一句话:对于数据量不大的站点,首选如何利用好 Cache 吧,分片只是手段,不是目的。事实上,如果不是涉及到每天上万的交易量,Cache才是更好的处理方案。当然象文中回答的对象来自腾讯,那当然,对于拍拍网、Q币等交易,几乎每天都是过万的交易量,这时候他们才会考虑使用所谓的数据分片。不过,了解一下这种技术或者说是手段,出去IB一下的时候也可以吹吹啊。。
原文来自:http://www.dbanotes.net/database/sharding.html,全文如下【未作删节】:
Question: 假设一家 C2C 网站,数据库中某表存储买卖双方交易的数据信息,对于一条交易来说,买卖双方数据具有一定程度的耦合性,比如卖家的状态更新对应买家的状态也会更新,对于 一个中大规模的电子商务网站,架构师在设计中如何考虑数据分片的问题(假定该表随着数据的膨胀必须拆分)?
Answer:对于一个中大规模的电子商务网站,随着网站的不断发展,其相应的数据规模会不断膨胀。数据分片技术是使网站得于实现可扩展性的一种常用解决方案。对于 C2C 类型的网站,由于交易记录不容易进行水平的数据分割,因此对于这样的应用处理要再进行细分:
这个问答是《程序员》杂志架构师接龙栏目的第一期的内容。提问者是我,回答者是腾讯研发总监王速瑜先 生。其实我抛出问题后当时还真不知道接龙的是哪位,只是知道会是百度或是腾讯的朋友来回答,当然我也对这两家的数据处理方式都是比较感兴趣的。最后刊登的 内容或许让很多人觉得不过瘾 -- 如果能更详细一点就好了(毕竟还有其他问题呢)。不过能够引发思考就好,这也是这个栏目的初衷吧。
对这个问题或许可以补充的是,切分或许还算是容易的事情,但是切分后用户对数据的查询多少是有点麻烦。一旦要查询历史交易信息,则必须考虑跨多个数 据分片获取数据并排序的问题。交易中的数据与交易完成的数据是否做切分,是有必要根据自己的实际情况仔细衡量。要注意如对交易中的活动数据单独存放的一个 表中,则还是不可避免的要产生 I/O 热点问题,而且,这个表实际上变成了一个数据队列(新的瓶颈)--新生成的交易进来,完成的交易删除或归档。这样产生的双重 I/O 压力不容忽视。
当然,这个问题的前提限制了回答的发挥,其实在设计初期也可以考虑买家信息与卖家信息分别放入不同的表中,然后对这两种属性的表再进行切分,这也是 可选的途径,这样的开销是每笔交易会重复存储一条记录,而记录的变化也要在两个表中更新。对数据的一致性维护有一定的挑战。这似乎是个只带来额外开销的办 法?其实也有益处--索引的设计起码会更简单一些,而用户对交易记录的定制查询也会更加方便。
数据分片(或 Sharding) 现在几乎是每个网站架构师都必须要考虑的基础问题。多数情况下,分片的粒度和方式取决于业务,慢慢地快变成可意会不可言说的话题了,你有什么建议或意见不妨留言说说。
--EOF--
为了避免误导,对于数据量不大的站点,首选如何利用好 Cache 吧,分片只是手段,不是目的。【这句话也是dbanotes.net所提出的。不是我说的,虽然我也是这个想法。。。黑黑】
| « 2026年06月 » | ||||||
| 日 | 一 | 二 | 三 | 四 | 五 | 六 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 | ||||
[666] [9] [38] [14] [2] [12] [307] [65] [289] [229] [161] [236] [9] [27] [14] [981] [92]