以前我曾经发贴说,VIM看汉字是乱码,当时我说的是ssh连接乱码,最后是通过更改服务器的language来解决的。
taobaoDBA的陶方则研究的比较深入,他认为:无论字符串采用了什么字符集,在内存和文件中的存储形式都是二进制的。出现乱码的原因是解释并显示二进制数据的字符集和产生二进制数据的字符集不能兼容引起的。
原文如下:
http://rdc.taobao.com/blog/dba/html/275_vim_charset_researc.html
- 字符集转换是个很麻烦的事情,特别是数据库的字符集转换,涉及到了很多细节。
- 为了引出更多的讨论,我这先抛个砖头,是关于vim编码的问题,希望大家看完能有所收获。
-
- 1、无论字符串采用了什么字符集,在内存和文件中的存储形式都是二进制的。出现乱码的原因是解释并显示二进制数据的字符集和产生二进制数据的字符集不能兼容引起的。
- 2、从一个字符集转换到另外一个字符集是可以做到的,但是必须要有代码去实现这个转换。有些时候是显式转换,有些时候是隐式转换。vim属于显式转换。
-
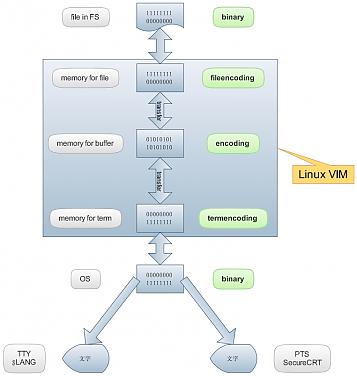
- vim有三个编码参数,分别是fileencoding(或fileencodings)、encoding、termencoding,根据字面理解,分别代表了文件的编码格式、缓存的编码格式、终端的编码格式。fileencoding和encoding不一致的时候,缓存中的数据会进行一次字符集转换,然后存入磁盘。当encoding和termencoding不一致的时候,缓存中的数据也会进行一次转换,然后以字节流的形式传给终端。终端(TTY)和伪终端(PTS)都有自己的编码格式。Linux的LANG即是TTY的编码格式,SecureCRT的字符集设置即是PTS的编码格式(无论是ssh和是telnet都一样)。如果不指定fileencoding、encoding、termencoding的编码格式,那么vim将会读取操作系统的字符集设置。实际上,只要正确设置这三个参数和SecureCRT,操作系统的字符集是不会影响远程查看和编辑文件(什么,你用emac?-。 -b)。
-
- --EOF--
还贴了一张图:
个人觉得以下内容不是特别成熟,不过可以用来做个参考。关于memcached做此类事情,张宴那里好象有不少资料,权当是参考吧?
全文如下:
http://www.cnblogs.com/xuanfeng/archive/2009/06/04/1494735.html
需求:
有个ASP.NET网站系统,有一级域名,二级域名,三级域名,系统的各个功能模块分布在不同的域名,同一域名的也有可能分布在不同省份的服务器或者同一同一省份的不同的服务器中,同一省份的的服务器可以通过内部局域网访问。在系统中,现在需要所有功能模块共享用户会话信私有数据。
常用的方式是启用Session的数据库持久会模式可以达到上面的需求(没尝试过),现在需要使用Memcached分布式缓存服务来达到保存用户的会话数据,而达到各个功能模块都能够跨省份、跨服务器共享本次会话中的私有数据的目的。
解决方案:
每个省份使用一台服务器来做为Memcached服务器来存储用话的会话中的数据,当然也可以多台服务器,但必须确保每个省份的做Memcached服务器数量必须一致,这样才能够保证Memcached客户端操作的是同一份数据,保证数据的一致性。
会话数据的添加、删除、修改:
Memcached客 户端,添加、删除和、修改会话信息数据时,不仅要添加、删除、修改本省的Memcached服务器数据,而且同时要对其它省份的Memcahed服务器做 同样的操作,这样用户访问其它省份的服务器的功能模块进也能读取到相同的会话数据。Memcached客户端服务器的列表使用局域网的内网 IP(如:192.168.1.179)操作本省的Memcahed服务器,使用公网的IP((如:202.183.62.210))操作其它省份的 Memcahe服务器。
会话数据的读取
系统所有模块读取会话数据的Memcached客户端服务器列表都设为本省Memcached服务器地址的内网IP来向Memcahed服务器中读取会话数据。
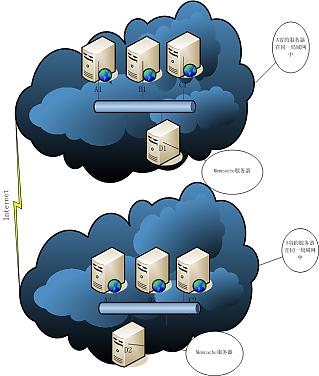
如 上图所示,A省有四台服务器,B省也有四台服务器,两个三份都有三台Web服务器、一台Memcached服务器,且A省四台服务器同在一个局域网内的可 能通过内网IP相互访问,B省也一样。假如:A省的A1,B1,C1这三台Web服务器其中的一台要添加或修改、或删除会话数据,它首先调服 Memcached客户端使服D1服务器的内网IP向D1服务器中添加或修改、或删除会话数据,操作完成后,还用调用Memcache客户端使服D2服务 器的公网IP向D2服务器做同样的操作,这样才算完整的操作过程,也可以当做一个事务来处理。假如:A省的A1,B1,C1这三台Web服务器其中一台服 务器想要读取会话的数据,只需要调用Memcached客户端使服D1服务器的内网IP读取数据即可,如果发现该数据不存在,即做向Memcached服 务器添加数据的相关业务处理。B省处理逻辑同A省。
同一会话的确认:
使用Cookie来保持客户与服务端的联系。 每一次会话开始就生成一个GUID作为SessionID,保存在客户端的Cookie中,作用域是顶级域名,这样二级、三级域名就可以共享到这个Cookie,系统中就使用这个SessionID来确认它是否是同一个会话。
会话数据的唯一ID
会话数据存储在Memcached服务器上的唯一键Key也就是会话数据数据的唯一ID定义为:SessionID_Name, SessionID就是保存在客户端Cookie中的SessionID, Name就是会话数据的名称,同一次会话中各个会话数据的Name必须是唯一的,否则新的会话数据将覆盖旧的会话数据。
会话的失效时间:
会话的失效通过控制Cookie的有效时间来实现,会话的时间设为SessionID或Cookie中的有效时间,且每一次访问SessionID时都要重新设置一下Cookie的有效时间,这样就达到的会话的有效时间就是两次间访问Cookie中SessionID值的的最长时间,如果两次访问的间隔时间超过用效时间,那么保存在SessionID的Cookie将会失效,并生成新的SessionID存放在Cookie中, SessionID改变啦,会话就结束啦。
Memcached服务器中会话数据的失效
每 一次向Memcache服务器中添加会话数据时,都把有效时间设为一天也就是24小时,让Memcached服务使用它内部的机制去清除,不必在程序中特 别做会话数据的删除操作。数据在Memcache服务器中有有效时间只是逻辑上的,就算是过了24 小时,如果分配给Memcached服务的内存还够用的话,数据还是保存在内存当中的,只是Memcache客户端读取不到而已。只有到了分配给 Memcached服务的内存不够用时,它才会清理没用或者比较旧的数据,也就是懒性清除。
关于张宴博客上一些memcached的资料,建议查看:http://blog.s135.com/category/13/
虽然对于存储session之类的没有介绍,但他介绍的分布式存储,如果运用起来就是实现上面的效果哦。。
本文来自kakapo的博客,kakapo,如果没有记错,应该是pchome的人吧。。。负载均衡我暂时还没有用到,毕竟我就一台服务器也没必要在服务器上装上17、8个虚拟机来跑这些负载均衡吧。
原文地址:http://www.kakapo.cn/blog/read.php?153
内容:
先罗列一下问题:
1、session会话数据共享问题
2、缓存数据文件共享问题
3、用户数据共享问题
4、上传数据存储问题
5、Log日志文件共享同步问题
6、配置文件管理问题
7、web服务器时间获取不一致问题
这些问题都是从项目经验中总结出来的,接下来在一一讨论解决的办法。
1、session会话数据共享问题
推荐使用memcached分布式缓存系统来解决,可以参考我之前写一篇文章《Memcached的介绍和应用》。
2、缓存数据文件共享问题解决方案
所谓缓存数据,一般指网站前台程序本身产生的数据,比如,数据库查询类产生的数据对象缓存,缓存类产生的本地缓存数据,远程抓取类产生的本地临时缓存文件等等。
有 些数据看似不需要共享,就像那些在每台机器上都能自动产生的数据。但是如果刚好碰到某个时刻数据更新了,缓存时间又不同步,就会造成负载均衡上的每台机器 缓存数据不相同。这也会给用户的访问带来一定的困扰。当然针对的解决办法就是想办法让缓存同时过期,保证缓存的内容相同,这就不需要考虑共享的问 题。
远程抓取经常会涉及到模拟登陆,在本地一般会保存模拟登陆用户的cookie数据,这个就一定得想办法解决共享。否则用户在负载 A机器上执行了模拟登陆程序,在本地产生了cookie文件,但是下次请求被分配到负载B机器上执行抓取程序,却发现需要用上的cookie文件在本地不 存在,马上程序就会被远程服务器拒绝访问。这种cookie的临时文件很多而且改动频繁。目前我们采用了NFS的方案,mount指定的一个缓存目录,让 负载的每台机器都能像本地目录一样访问,暂且还行的通。也可以将这个单独的应用放到一台机器,来避免这个问题。
3、用户数据共享问题
所谓用户数据,范围比较广。这里一般指在用户的独立目录空间保存的用户独用的数据。比例用户自己的相片,头像等等。
之 前我们采用的方法是搞一台存储服务器,通过一定的规则为用户创建目录空间,然后存储服务器通过NFS共享到所有负载均衡的web服务器。这种做法在几百万 用户的网站还行得通。主要问题在于NFS在高并发访问下会出现一些不稳定,会丢失文件访问句柄。另外还有mount管理带来的麻烦,以及数据安全等风险。 顺便提起用户目录空间的创建规则,分散均匀是一个最大的原则,采用哈希值切分方式比较合适。 采用用户名或者时间因子虽然方便了一些记忆和查询,但是容易碰到局部目录达到系统最大限制的问题。
所以,推荐使用分布式文件系统解决方案。国人happy_fish100开发了一个高效的开源的分布式文件系统FastDFS,比较完善,使用简单,功能强大。特别适合解决我当前遇到的问题。自称比国外的Mogilefs还强大。让我更心动的是提供了PHP client API,采用socket访问。在应用中调用也非常方便。
4、上传数据存储问题
这 个问题再单独拿出来谈是有根据的。在前台用户上传的自己相关的数据可以归属前面一个问题的范畴。前台也有一些用户上传的数据跟用户无关,还有网站后台也会 有很多上传的数据。之前的做法可以是通过FTP服务将这些数据上传到存储静态文件的服务器上,也有通过NFS方式共享静态文件服务器的指定目录到web服 务器。现在除了FTP方案之外,我也推荐尝试使用FastDFS来管理静态文件服务器的数据,但是要修改一下设计,可以在FastDFS的storge服 务器上直接架设http服务器,让静态文件能直接通过URL访问。
5、Log日志文件共享同步问题
所谓的Log日志也是web服务器程序自动产生的,比如错误日志,访问日志等。在一般情况一下也可以考虑让其不共享,无非是分析日志的时候每台机器都要做一遍。
6、配置文件管理问题&web服务器时间获取不一致问题
配置文件管理问题严格来讲不属于开发遇到的问题,而是运维人员烦恼的事情。当然,通过合理的将配置文件进行归类和存储,还是可以减少运维人员的困难的。web服务器的配置文件的最好也不用共享,文件的同步可以让系统管理员通过系统命令去自动完成。
web服务器时间不一致虽然可以通过系统定时跟全球的时间服务器同步,但是在开发过程中程序还是要尽量避免使用本地时间函数,特别是跟数据库有关系的数据,可以通过采用数据库的时间函数来解决。
Ubuntu的创始人Mark Shuttleworth最近对桌面Linux以及其未来发表了一些比较重要的言论,他说Linux的未来不在对Windows的兼容性上面。在其发言中,他特意提到了Wine这个程序——这是一个可以在Linux上提供对Windows程序的支持的程序,如果要想从Windows迁移到Linux,而你有些程序无法割舍,使用它再好不过,而且很多时候你会发现你想要的程序在Windows下才有。
Mark Shuttleworth称,类似Wine的兼容Windows的程序或者工程其重要程序不言而喻,但Linux的未来不在于对Windows的兼容性。 Linux与Windows有着本质的区别。linux作为自由软件,这个平台是否成功要依靠自身的发展,如果使用linux只是一种运行Windows 程序的媒介,那么linux永远不会有成功的那一天。
虽然他仅仅针对Ubuntu发表以上言论,但是很显然这番言论对任何linux版本都是合适的。正如他所说,在linux模拟运行 Windows程序并不能很好的抢占这个市场。linux开发者应该把重点放在核心应用上,让linux也可实现所有Windows才可实现的功能。
原文:alect
来自:http://www.cnbeta.com/articles/83517.htm
我的笔记本装上ubuntu后,只能使用4小时不到,但使用xp可以将近7小时。所以看到这个标题的时候就激动的记录了下来。。
原文:http://hutuworm.blogspot.com/2009/04/linux.html
1. Linux Kernel 2.6.21 开始支持 Tickless(此前的内核默认设置为 1000Hz timer tick),于是系统空闲时不再无故骚扰 CPU,可以节省大量能耗。Fedora 7+ 以及目前的 Ubuntu Linux 发行版都含有 Tickless 特性,而 RHEL 则要到版本 6 才会随新版本内核正式支持该特性(预计 2010年上市)。检查你的 Linux 系统是否支持 Tickless: watch --interval=1 cat /proc/interrupts ,若 timer 中断值并非以 1000 为步进单位增加,则说明该内核支持 Tickless。
2. 编译内核(make menuconfig):
- 启用 Tickless: Processor type and features -> [*] Tickless System (Dynamic Ticks)
- 启 用 CONFIG_USB_SUSPEND: Device Drivers -> USB support -> [*] USB selective suspend/resume and wakeup (自动禁用 UHCI USB,可以节省约 1 watt)
3. PowerTOP 可以找出计算机闲置时哪些进程耗电最多。(Kernel Hacking -> [*] Collect kernel timers statistics) 详见: http://www.lesswatts.org/projects/powertop/
4. 启用 power aware CPU scheduler(Scheduler Power Saving Mode): echo 1 > /sys/devices/system/cpu/sched_mc_power_savings
5. RHEL 5.3 支持 Intel Core i7 (Nehalem) 的电源管理功能。
6. 启用 irqbalance 服务,既可以提升性能,又可以降低能耗。irqbalance 用于优化中断分配,它会自动收集系统数据以分析使用模式,并依据系统负载状况将工作状态置于 Performance mode 或 Power-save mode。处于 Performance mode 时,irqbalance 会将中断尽可能均匀地分发给各个 CPU core,以充分利用 CPU 多核,提升性能。处于 Power-save mode 时,irqbalance 会将中断集中分配给第一个 CPU,以保证其它空闲 CPU 的睡眠时间,降低能耗。(详见:http://www.irqbalance.org/documentation.php )
7. 禁用 pcscd,该进程会阻碍 USB 子系统进入 Power-save mode。
8. 将 VM dirty writeback time 延长至 15 秒: echo 1500 > /proc/sys/vm/dirty_writeback_centisecs
9. 启用 noatime 文件系统选项: mount -o remount,noatime / (noatime 禁止更新 atime,可以节省大量 I/O,但为了避免 atime 相关应用程序出现问题,建议启用 relatime 代之: mount -o remount,relatime / ,relatime 自 Kernel 2.6.29 起为默认设置。)
10. 禁止 hal 轮询你的 cdrom: hal-disable-polling --device /dev/cdrom
* 关于 Linux 节能的更多信息,请看: http://www.lesswatts.org