同样,是一篇摘录,笔记。勿怪。。。
原文:http://www.cnblogs.com/chenlong828/archive/2008/09/22/1296193.html
作者:dreamland
查阅了一下网络和博客园,发现还没有一个明确地指导源码管理提交准则的相关文章,因此斗胆整理了一部分自己平时开发管理的心得,加上查阅了部分英文资料写了一个不算很完善的SVN提交准则。
负责而谨慎地提交自己的代码
SVN更新的原则是要随时更新,随时提交。当完成了一个小功能,能够通过编译并且并且自己测试之后,谨慎地提交。
如果提交过程中产生了冲突,则需要同之前的开发人员联系,两个人一起协商解决冲突,解决冲突之后,需要两人一起测试保证解决冲突之后,程序不会影响其他功能。
如果提交过程中产生了更新,则也是需要重新编译并且完成自己的一些必要测试,再进行提交。
保持原子性的提交
每次提交的间歇尽可能地短,以一个小时,两个小时的开发工作为宜。如在更改UI界面的时候,可以每完成一个UI界面的修改或者设计,就提交一次。在开发功能模块的时候,可以每完成一个小细节功能的测试,就提交一次,在修改bug的时候,每修改掉一个bug并且确认修改了这个bug,也就提交一次。我们提倡多提交,也就能多为代码添加上保险。
不要提交自动生成的文件
Visual Studio在生成过程中会产生很多自动文件,如.suo等配置文件,Debug,Release,Obj等编译文件,以及其他的一些自动生成,同编译代码无关的文件,这些文件在提交的时候不应该签入,如果不小心签入了,需要使用Delete命令从仓库中删除。
不要提交不能通过编译的代码
代码在提交之前,首先要确认自己能够在本地编译。如果在代码中使用了第三方类库,要考虑到项目组成员中有些成员可能没有安装相应的第三方类库或者没有放入GAC(针对.Net Framework)中,项目经理在准备项目工作区域的时候,需要考虑到这样的情况,确保开发小组成员在签出代码之后能够在统一的环境中进行编译。
不要提交自己不明白的代码
代码在提交入SVN之后,你的代码将被项目成员所分享。如果提交了你不明白的代码,你看不懂,别人也看不懂,如果在以后出现了问题将会成为项目质量的隐患。因此在引入任何第三方代码之前,确保你对这个代码有一个很清晰的了解。
提前宣布自己的工作计划
在自己准备开始进行某项功能的修改之前,先给工作小组的成员谈谈自己的修改计划,让大家都能了解你的思想,了解你即将对软件作出的修改,这样能尽可能的减少在开发过程中可能出现的冲突,提高开发效率。同时你也能够在和成员的交流中发现自己之前设计的不足,完善你的设计。
对提交的信息采用明晰的标注
+) 表示增加了功能
*) 表示对某些功能进行了更改
-) 表示删除了文件,或者对某些功能进行了裁剪,删除,屏蔽。
b) 表示修正了具体的某个bug
又是一篇记录,摘要,原文来自:http://cwg.bloghome.cn/posts/75845.html
svn命令 通常都有帮助,可通过如下方式查询:
$ svn help
知道了子命令,但是不知道子命令的用法,还可以查询:
$ svn help add
开发人员常用命令
(1) 导入项目
$ cd ~/project
$ mkdir -p svntest/{trunk,branches,tags}
$ svn import svntest https://localhost/test/svntest --message "Start project"
...
$ rm -rf svntest
我们新建一个项目svntest,在该项目下新建三个子目录:trunk,开发主干;branches,开发分支;tags,开发阶段性标签。然后导入到版本库test下,然后把svntest拿掉。
(2) 导出项目
$ svn checkout https://localhost/test/svntest/trunk
修订版本号的指定方式是每个开发人员必须了解的,以下是几个参考例子,说明可参考svn推荐书。
$ svn diff --revision PREV:COMMITTED foo.c
# shows the last change committed to foo.c
$ svn log --revision HEAD
# shows log message for the latest repository commit
$ svn diff --revision HEAD
# compares your working file (with local changes) to the latest version
# in the repository
$ svn diff --revision BASE:HEAD foo.c
# compares your “pristine” foo.c (no local changes) with the
# latest version in the repository
$ svn log --revision BASE:HEAD
# shows all commit logs since you last updated
$ svn update --revision PREV foo.c
# rewinds the last change on foo.c
# (foo.c's working revision is decreased)
$ svn checkout --revision 3
# specified with revision number
$ svn checkout --revision {2002-02-17}
$ svn checkout --revision {15:30}
$ svn checkout --revision {15:30:00.200000}
$ svn checkout --revision {"2002-02-17 15:30"}
$ svn checkout --revision {"2002-02-17 15:30 +0230"}
$ svn checkout --revision {2002-02-17T15:30}
$ svn checkout --revision {2002-02-17T15:30Z}
$ svn checkout --revision {2002-02-17T15:30-04:00}
$ svn checkout --revision {20020217T1530}
$ svn checkout --revision {20020217T1530Z}
$ svn checkout --revision {20020217T1530-0500}
(3) 日常指令
$ svn update
$ svn add foo.file
$ svn add foo1.dir
$ svn add foo2.dir --non-recursive
$ svn delete README
$ svn copy foo bar
$ svn move foo1 bar1
$ svn status
$ svn status --verbose
$ svn status --verbose --show-updates
$ svn status stuff/fox.c
$ svn diff
$ svn diff > patchfile
$ svn revert README
$ svn revert
修改冲突发生时,会生成三个文件:.mine, .rOLDREV, .rNEWREV。比如:
$ ls -l
sandwich.txt
sandwich.txt.mine
sandwich.txt.r1
sandwich.txt.r2
解决修改冲突方式之一:修改冲突的文件sandwich.txt,然后运行命令:
$ svn resolved sandwich.txt
方式之二:用库里的新版本覆盖你的修改:
$ cp sandwich.txt.r2 sandwich.txt
$ svn resolved sandwich.txt
方式之三:撤销你的修改,这种方式不需要运行resolved子命令:
$ svn revert sandwich.txt
Reverted 'sandwich.txt'
$ ls sandwich.*
sandwich.txt
确保没问题后,就可以提交了。
$ svn commit --message "Correct some fatal problems"
$ svn commit --file logmsg
$ svn commit
(4) 检验版本历史
$ svn log
$ svn log --revision 5:19
$ svn log foo.c
$ svn log -r 8 -v
$ svn diff
$ svn diff --revision 3 rules.txt
$ svn diff --revision 2:3 rules.txt
$ svn diff --revision 4:5 http://svn.red-bean.com/repos/example/trunk/text/rules.txt
$ svn cat --revision 2 rules.txt
$ svn cat --revision 2 rules.txt > rules.txt.v2
$ svn list http://svn.collab.net/repos/svn
$ svn list --verbose http://svn.collab.net/repos/svn
$ svn checkout --revision 1729 # Checks out a new working copy at r1729
…
$ svn update --revision 1729 # Updates an existing working copy to r1729
…
(5) 其他有用的命令
svn cleanup
为失败的事务清场。
(6) 分支和合并
建立分支方法一:先checkout然后做拷贝,最后提交拷贝。
$ svn checkout http://svn.example.com/repos/calc bigwc
A bigwc/trunk/
A bigwc/trunk/Makefile
A bigwc/trunk/integer.c
A bigwc/trunk/button.c
A bigwc/branches/
Checked out revision 340.
$ cd bigwc
$ svn copy trunk branches/my-calc-branch
$ svn status
A + branches/my-calc-branch
$ svn commit -m "Creating a private branch of /calc/trunk."
Adding branches/my-calc-branch
Committed revision 341.
建立分支方法二:直接远程拷贝。
$ svn copy http://svn.example.com/repos/calc/trunk \
http://svn.example.com/repos/calc/branches/my-calc-branch \
-m "Creating a private branch of /calc/trunk."
Committed revision 341.
建立分支后,你可以把分支checkout并继续你的开发。
$ svn checkout http://svn.example.com/repos/calc/branches/my-calc-branch
假设你已经checkout了主干,现在想切换到某个分支开发,可做如下的操作:
$ cd calc
$ svn info | grep URL
URL: http://svn.example.com/repos/calc/trunk
$ svn switch http://svn.example.com/repos/calc/branches/my-calc-branch
U integer.c
U button.c
U Makefile
Updated to revision 341.
$ svn info | grep URL
URL: http://svn.example.com/repos/calc/branches/my-calc-branch
合并文件的命令参考:
$ svn diff -r 343:344 http://svn.example.com/repos/calc/trunk
$ svn merge -r 343:344 http://svn.example.com/repos/calc/trunk
$ svn commit -m "integer.c: ported r344 (spelling fixes) from trunk."
$ svn merge -r 343:344 http://svn.example.com/repos/calc/trunk my-calc-branch
$ svn merge http://svn.example.com/repos/branch1@150 \
http://svn.example.com/repos/branch2@212 \
my-working-copy
$ svn merge -r 100:200 http://svn.example.com/repos/trunk my-working-copy
$ svn merge -r 100:200 http://svn.example.com/repos/trunk
$ svn merge --dry-run -r 343:344 http://svn.example.com/repos/calc/trunk
最后一条命令仅仅做合并测试,并不执行合并操作。
建立标签和建立分支没什么区别,不过是拷贝到不同的目录而已。
$ svn copy http://svn.example.com/repos/calc/trunk \
http://svn.example.com/repos/calc/tags/release-1.0 \
-m "Tagging the 1.0 release of the 'calc' project."
$ ls
my-working-copy/
$ svn copy my-working-copy http://svn.example.com/repos/calc/tags/mytag
Committed revision 352.
后一种方式直接把本地的工作拷贝复制为标签。
此外,你还可以删除某个分支。
$ svn delete http://svn.example.com/repos/calc/branches/my-calc-branch \
-m "Removing obsolete branch of calc project."
管理人员常用命令
(7) 版本库管理
$ svnadmin help
...
$ svnadmin help create
...
$ svnadmin create --fs-type bdb /usr/local/repository/svn/test
$ chown -R svn.svn /usr/local/repository/svn/test
建立版本库,库类型为bdb(使用Berkeley DB做仓库),库名称为test。
svn版本库有两种存储方式:基于Berkeley DB(bdb)或者基于文件系统(fsfs),通过 --fs-type可指定存储方式。
(8) 查询版本库信息
$ svnlook help
...
$ svnlook help tree
...
$ svnlook tree /usr/local/repository/svn/test --show-ids
网上的资料,都是用svn update命令在post-commit里面进行同步,这里面很多人都忽略了讲最重要的一点,那就是在svn update之前,该目录必须要先用svn checkout一下,否则。update目录会直接忽略该目录。
这,几乎所有的教程里都没讲,我是试了半天啊。。。
后来,也找到了一篇类似教程。希望看到的人少走点弯路。
原文:http://www.unix-center.net/bbs/viewthread.php?tid=11607
Linux环境下配置同步更新的SVN服务器
先搭建环境
Linux版本选择Centos5.0(
膘叔:我是用的ubuntu,具体的安装方法可以参考我的上篇step by step安装svu for ubuntu)
#yum update
#yum -y install gcc
#yum -y install httpd
#yum install mod_dav_svn subversionDependencies Resolved
初期配置 我选择的是以HTTP方式实现SVN功能
cd /etc/httpd/conf.d/
vi subversion.conf
添加以下内容
# Make sure you uncomment the following if they are commented outLoadModule dav_svn_module
LoadModule dav_svn_module modules/mod_dav_svn.so
LoadModule authz_svn_module modules/mod_authz_svn.so
# Add the following to allow a basic authentication and point Apache to where the actual# repository resides.
<Location /boqii> #访问域名,设置后可以直接用
http://127.0.0.1/boqii来访问了
DAV svn
SVNPath /svn/boqii #SVN建立的版本数据库位置
AuthType Basic
AuthName "Subversion boqii"
AuthUserFile /etc/svn-auth-conf
Require valid-user
</Location>
建立SVN的用户和权限设置
建立第一个用户
htpasswd -cm /etc/svn-auth-conf woody
然后根据提示输入密码并且确认密码,以后再建立用户就不需要再加上参数-c了
htpasswd -m /etc/svn-auth-conf keen
htpasswd -m /etc/svn-auth-conf harry
建立版本数据库
cd /
mkdir svn
cd svn
svnadmin create boqii
chown -R apache.apache boqii
设置APACHE发布信息
DocumentRoot "/www"
<Directory "/www">
Options FollowSymLinks
AllowOverride None
Order allow,deny
Allow from all
</Directory>
service httpd start
建立导入目录
cd /
mkdir www
chmod 755 www
chown apache.apache /www
配置钩子程序
[root@www /]# cd /svn/boqii/hooks/
[root@www hooks]# cp post-commit.tmpl post-commit
[root@www hooks]# chmod 755 post-commit
[root@www hooks]# chown apache.apache post-commit
[root@www hooks]# vi post-commit
将里面的所有代码全部注释
添加以下这行代码
svn update --username=woody --password=woody
http://127.0.0.1/boqii /www
然后保存退出
导出版本version:0的数据库内容
svn checkout --username=woody --password=woody
http://127.0.0.1/boqii /www
配置完毕,重启一下APACHE服务器试试看
service httpd restart
参考文章
在 FreeBSD 下架設 Subversion
最简单的SVN (subversion)的配置for centos
Version Control with Subversion我的博客 www.yidaman.com 欢迎大家多多交流
看到这篇文章,就随手转贴了一下,因为我自己也在使用这样的功能,而且,现在的网站几乎都有google的广告。所以从yahoo的14条军规来说,这并不违反这个规则:使用CDN,尽量不要有超过4个域名的链接。所以你想呀,有一些google广告和yahoo的统计再加上1至2个其他的链接,肯定是没有超过4个域名了。CDN,有现成的,使用了,也算是完成了14条军规中的一些了。不是吗?所以。。。。。。
原文:http://shawphy.com/2009/01/why-google-cdn.html
自从之前jQuery 1.3版起,就已经没有提供pack版了,而我也十分赞成使用Google CDN进行代码托管。
这样做有以下几个好处:
1,更小下载量。
都知道jQuery 1.3 pack后有38k之多,如果当然可以删除版权注释以获得更小的代码,遗憾的是这不仅无耻且只节约1个k都不到。而同样利用Google APIs 提供的GZip过的Min版,只有18k,对用户来说下载量更小。
2,减轻服务器压力。
虽然现代浏览器都有了缓存,但以前我看到过资料说某大型网站发现他们70%的访客缓存都是空的(哪位同学能帮忙找到资料请下面留言,不胜感激~)。所以,让Google为我们提供服务,而不用自己操心自己的流量~少个库可以少个连接数,何乐而不为。
3,多个网站共享缓存。
如果用户访问的多家网站都使用Google提供的jQuery,那么对于用户来说,只需要缓存一次后即可只读取缓存中的数据!而不是每个网站都要重新下载一份。对此进一步加快用户访问速度。
4,更快执行速度。
jQuery 1.3.1发布的发布信息中, 为jQuery不提供pack版给出了官方的解释。除了不易debug,在Adobe AIR和Caja-capable等环境下无法使用之外,更重要的是因为执行速度问题。随着jQuery逐渐变“胖”,用pack压缩后在浏览器端“解压 缩”所需要的资源越来越大。想象一个超大的字符串多次replace后再eval的情景……这不比直接读取一个不需要解压缩的min版来得快。John给 出了一些数据,有兴趣的同学可以看看。
反对的声音:
“不安全”、“没安全感”、“放别人的机器太危险了”、“他们服务器倒了呢?”、“以前刚开始的时候就down过”
我认为(晕……怎么我觉得我在写四六级作文……)Google服务器down的几率与我们自己服务器down的几率不会有显著性差异(抱歉,我又空 口无凭说话了……不过如果哪位同学能给出数据来拒绝我的零假设,认可备选假设的,欢迎提供,再次不胜感激~)。所以就放他们那边吧,挺安全的。
另外我还听到关于不能让整个世界为着Google转,Google阴谋论,Google威胁论的声音。实际上Google确实正朝这个方向发展,让 整个互联网围着他转。可以看他提供的一些服务,什么云计算,什么App Engine之类的,都企图让人们的应用都建立在Google至上,当Google成为了空气的时候,他已经无处不在了。这点来说,值得担忧。
身为一名WEB开发人员,对于WEB通信当然是非常关心的,对于每一个POST甚至都有可能要抓包 进行分析,但究竟怎么做,用什么做,如何去做,还是有点讲究的。我个人是习惯用fireBug和webdeveloper还有IE下的httpwatch等进行分析。看到这篇文章的介绍,也可以看看别人是怎么做,取别人的之长补自己之短才能有进步嘛。。
原文链接:http://tech.idv2.com/2008/12/30/web-comm-analyzer/
原文作者:charlee
内容如下:(图片下载到了本地了)
在抓虾上看到一篇Web开发分析工具的文章(链接就免了),怎么远没有我用的东西好用呢? 还是介绍介绍我用的吧。由于平常开发只用FireFox,完成后再去调试IE, 所以这些工具绝大部分是针对FireFox的。
如果把Web通信从上到下分为许多层——XMLHttpRequest层,HTTP层,TCP层, 那么这些工具可以分别抓取每个层的通信数据进行分析,结合使用极其强大。
2008/12/31:另外可以参考daniel同学的Web开发常用工具一文,相信会大有帮助哦。
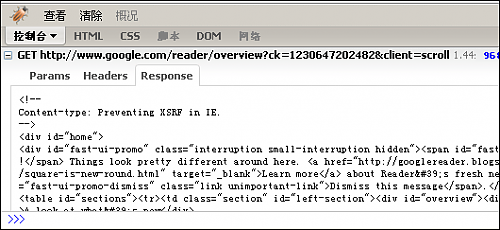
XMLHttpRequest层:Firebug
| 适用范围 |
Ajax应用程序 |
| 优点 |
使用方便,数据截取完整 |
| 缺点 |
只能分析XMLHttpRequest请求,其他类型的请求无能为力 |
Firebug应该是尽人皆知了。 它的控制台能监视XMLHttpRequest请求,能看到完整的请求和应答的数据。 用它来调试Ajax程序是最好不过了。
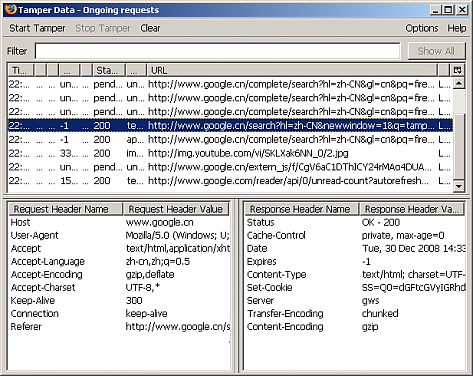
HTTP层:Tamper Data
| 适用范围 |
普通网页,Ajax应用程序,Flash |
| 优点 |
使用方便,适用范围广,任何HTTP请求都能截获 |
| 缺点 |
只能截获请求头、请求内容、应答头,得不到应答内容;涉及文件下载时效率大幅度降低 |
Tamper Data比Firebug进了一步, 只要是HTTP请求,它都能抓下来,可惜的是看不到应答内容。 适用于分析请求流程、请求参数、请求数据、重定向URL。 对于非Ajax程序如普通网页、Flash、ActiveX等程序,用Tamper Data来分析十分方便。
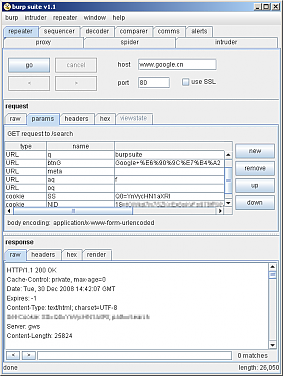
HTTP层:burpsuite
| 适用范围 |
普通网页,Ajax应用程序,Flash |
| 优点 |
适用范围广,截取数据完整,不挑网卡 |
| 缺点 |
使用稍稍麻烦 |
burpsuite中的proxy功能用于分析Web通信十分好用。 它的原理是架设一个代理服务器,让浏览器通过代理来发送请求,代理就可以截获数据了。
使用方法为:
- 配置proxy,然后设置浏览器使用它的proxy
- 访问想要抓取的那个网页
- burp suite的proxy中就会看到请求内容,在这里即可详细地分析请求。
- 如果想继续分析应答,可以右键点击请求内容,选send to repeater
- 切换到repeater标签,点【go】按钮发送请求,在下方就可以看到应答
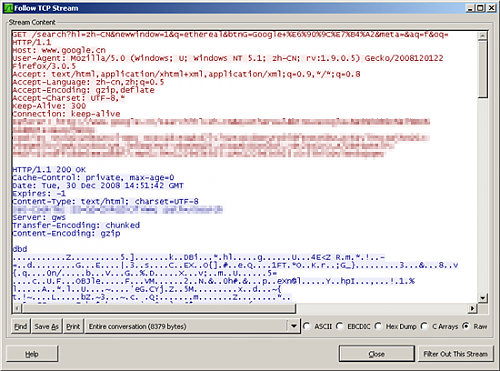
TCP层:wireshark
| 适用范围 |
任何网络程序 |
| 优点 |
适用范围广,截取数据完整 |
| 缺点 |
使用麻烦;不能使用loopback网卡 |
如果以上方法都不管用,就要祭出终极武器wireshark(原名ethereal)了。 它从网络的最底层入手,可以截获任何类型的网络通信,而不仅仅是HTTP协议。 比如要开发一个邮件程序,需要分析服务器端脚本与POP3服务器之间的通信, 那就非得wireshark出马不可了。
使用方法:
- 在wireshark中选择抓取物理网卡;
- 让应用程序发请求;
- 在wireshark中停止抓取;
- 从抓到的包一览中找出刚才应用程序发出的请求,右键点击选择 Follow TCP Stream,就能看到该请求的完整内容。
这个工具的不足之处是它不能抓取loopback的网卡,也就是说, 如果你的程序连接的是位于localhost或127.0.0.1的服务器, 那wireshark是抓不到的。解决方法是,让程序通过真实物理网卡去连别的机器, 或是使用虚拟机的虚拟网卡也行。