Submitted by gouki on 2008, October 18, 9:27 PM
原文来自博客园,把代码全部翻译成了PHP的,因为这些东西对PHP同样适用。
函数递归调用是很常见的做法,但是它往往是低效的,本文探讨优化递归效率的思路。
1.尾递归转换成迭代
尾递归是一种简单的递归,它可以用迭代来代替 比如 求阶乘函数的递归表达
PHP代码
- <?php
- function f( $n = 0)
- {
- if($n<=0)return 1;
- return $n*f($n-1);
- }
- ?>
可以转换成完全等价的循环迭代
PHP代码
- <?php
- function f($n = 0)
- {
- $r=0;
- while( $n-- > 0)
- $r *= $n;
- return $r;
- }
- ?>
尾递归是最简单的情形,好的编译器甚至可以自动的识别尾递归并把它转换成循环迭代。
更多看详细
» 阅读全文
Tags: php, 递归, 效率, 优化
PHP | 评论:1
| 阅读:29168
Submitted by gouki on 2008, October 7, 11:46 AM
小家伙今天理了个小光头,不过还不算是太光,外婆不让。唉。胎毛还是留了点在头上。
上张照片。。。
图片附件(缩略图):
Tags: 佑阳, 光头, 照片
Scala & Ruby | 评论:3
| 阅读:24424
Submitted by gouki on 2008, October 4, 7:03 PM
博客本来就是用来记录内心想法的东西,只是我的博客可能记录的技术类的东西相对较多,国庆期间嘛,心思也不在技术上,于是就有了杂谈。
美国众议院、参议院终于同意了救市方案,7000亿美金,听起来很恐怖,可惜股市还是下跌了,恐怕华尔街那些人就非常开心了,压力会小一点了。我在上篇杂谈里就说过,不希望会有这种事情发生,毕竟有第一次也就会有第二次。布什在促进这件事成功,是因为不想留下污点?个人认为。两个竞选者促进成功,是因为这样可以在上台后压力小一点,反正用的钱又不是我的,也不是我下令的,责任不在我身上。可惜对于美国这种物权法很看中的国家来说,民众是怎么想的?7000亿,要纳多少税?在用自己的钱救市,心里是迷惘多一点还是期盼多一点?我交出去的钱,终于派上用场了?可惜,华尔街人应该也在想,怕啥,再怎么样,还是会有人帮我的。。。
除开经济,恐怕搞技术的人这两天都在关注着GOOGLE推出的在线备份MYSQL的innodb数据库?这里提到了,这里也提到了,其实讲的都是GOOLE CODE上的内容,谁来做小白鼠?短时间内谁敢用?估计还是要过段时间了,不过,这毕竟是一个想法,以后这种类似的东西会越来越多的吧?
再说说软件,思维导图,应该算是最近一段时间比较流行的东西了,思维导图是国内人员的翻译,详细介绍如下:
什么是MindManager?
-
- MindManager是一个创造、管理和交流思想的通用标准,其可视化的绘图软件有着直观、友好的用户界面和丰富的功能,这将帮助您有序地组织您的思维、资源和项目进程。
-
- MindManager也是一个易于使用的项目管理软件,能很好提高项目组的工作效率和小组成员之间的协作性。它作为一个组织资源和管理项目的方法,可从脑图的核心分枝派生出各种关联的想法和信息。
- MindManager可以使讨论和计划的过程从根本上发生变化,促进实现你的思想和方案。
- 在一般的传统的讨论中至少包含四个步骤:
- 1、从图表或白板上获得思想
- 2、转录成为很难阅读的电子版
- 3、在组织信息资料的过程中不可避免的要损失某些思想的重要关系
- 4、通过印刷品或者电子邮件分发资料
- 时间和资源在重复的信息中被浪费了,同事们很难理解会议的结果。
- 但是,MindManager软件改变了研讨过程,只通过以下两个步骤就可以在同一页中显示出每个人的观点,从而避免了不必要的重复性的工作。
- 1、迅速的以可视化形式获取和组织思想,促进团队内的协作和个体积极性。
- 2、能够直接分发会议记录,比以往更快的落实各种设想。
- 点击“输出”(export),可以得到PDF、Word、Powerpoint、HTML和图片格式文件。
cnbeta上面有详细介绍,上面的也是COPY而来,地址为:http://www.cnbeta.com/articles/66193.htm,除了这个软件,另外这五款软件也是不错的,值得下载使用,我没有用过,但是看名称和介绍,就知道应该是值得用用:
5个最出色必须拥有的windows xp 管理插件
Tags: 杂谈, google, mysql, 股票
Misc | 评论:0
| 阅读:21743
Submitted by gouki on 2008, September 27, 8:07 PM
做网站的人关心的是怎么样能够被更多的收录,毕竟收录的越多,被搜索的机会也就越大,被搜索的机会越大,被收录的也就会更多,这是一个良性循环。
对于这一点google的PAGERANK也算是一个门槛,相比较而言,PR值越高的网站,GOOGLE等爬虫就会越关注这个网站,如果上面的资料多,那么被收录的机会就会大大增加。
SEO做的就是这些功能。。
今天pr大更新,欣慰的是neatstudio.com的PR终于升到5了,neatcn.com的PR升到3,然而,52cd.net的PR降为1了,原来是3啊。心痛中。。。
不过,升到5也算是一个好消息了。52cd.net的,我以后会慢慢补回来的。。哼
neatcn.com的alexa rank是342050了,一切在向好的方面发展
谨以此文纪念一下这些数值,OHYEAH.
Tags: pagerank, google, pr
Misc | 评论:0
| 阅读:20869
Submitted by gouki on 2008, September 24, 9:42 AM
Imagick的DLL在windows上本来无法装上,前面一篇博客里介绍说团队好友hihiyou帮忙找了一个DLL,可以用在PHP 5.2.X上面的,今天一大早COPY到服务器上,并扩展出来。。
看图说话,OH YEAH。可惜。。。sablog不支持Imagick,它还是用GD的,不知道新版本会不会采用。
好象小图看不太清楚。还是点击一下看大图吧。。。
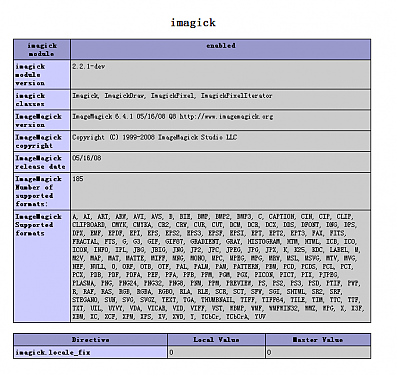
Tags: imagick, 安装
PHP | 评论:6
| 阅读:32902

