
我知道INNODB不錯,但是我的VPS只有小小的512M內存,實在是扛不住,這玩意啥也不錯就吃掉了我不少內存了。於是我直接在my.cnf裏加上了skip-innodb。結果服務無法啟動。
找了一下資料 ,原來mysql 5.5以上的時候,默認的引擎就是innodB,因此,如果要skip掉它,必須告訴 mysql我的默認引擎是myisam。因此代碼就變成了這樣,在[mysqld]中加入:
default-storage-engine = MyISAM
然後再skip-innodb,接著運行service mysql restart,世界清靜 了。
原來運行top的時候,mysql一直佔有著70%左右的CPU。現在立刻清零。
一下子安逸了
浏览模式: 标准 | 列表Tag:innodb
在VPS上为mysql禁用innodb引擎
Submitted by gouki on 2012, July 10, 9:11 AM
清除数据库的binlog
Submitted by gouki on 2010, December 28, 4:35 PM
如果数据库中没有什么太过重要的数据,每隔一段时间还是清除一下binlog吧。这玩意,对于没重要数据的人来说,实在没有意义 。。。。
大多数用binlog的,往往都是在wordpress上。因为它默认是innodb(好象3.01安装的时候,默认是myisam了。。至少我装的某一个库就是myisam的,很意外)
怎么清除bin log呢?先进入数据库命令行
show master logs;
purge master logs to 'mysql-bin.000010';
一般情况看看到最后一个是啥就留到啥吧。。。
留着最近的,真要出啥事了,还能恢复一下。。(不过,有多少人在自己的机器上恢复数据的?公司的除外。。。。)
看51CTO上两篇MYSQL引擎该如何选择的文章
Submitted by gouki on 2010, January 3, 1:21 PM
MYISAM和INNODB的争论由来已久,如今,我又找到两篇文章,让我们看看有关这两种引擎的优劣的文章:浅谈MySQL存储引擎选择 InnoDB还是MyISAM以及InnoDB还是MyISAM 再谈MySQL存储引擎的选择
第一篇:浅谈MySQL存储引擎选择 InnoDB还是MyISAM
作者:酷壳,来源于:http://database.51cto.com/art/200905/122382.htm
MyISAM 是MySQL中默认的存储引擎,一般来说不是有太多人关心这个东西。决定使用什么样的存储引擎是一个很tricky的事情,但是还是值我们去研究一下,这里的文章只考虑 MyISAM 和InnoDB这两个,因为这两个是最常见的。
下面先让我们回答一些问题:
◆你的数据库有外键吗?
◆你需要事务支持吗?
◆你需要全文索引吗?
◆你经常使用什么样的查询模式?
◆你的数据有多大?
思考上面这些问题可以让你找到合适的方向,但那并不是绝对的。如果你需要事务处理或是外键,那么InnoDB 可能是比较好的方式。如果你需要全文索引,那么通常来说 MyISAM是好的选择,因为这是系统内建的,然而,我们其实并不会经常地去测试两百万行记录。所以,就算是慢一点,我们可以通过使用Sphinx从 InnoDB中获得全文索引。
数据的大小,是一个影响你选择什么样存储引擎的重要因素,大尺寸的数据集趋向于选择InnoDB方式,因为其支持事务处理和故障恢复。数据库的在小 决定了故障恢复的时间长短,InnoDB可以利用事务日志进行数据恢复,这会比较快。而MyISAM可能会需要几个小时甚至几天来干这些事,InnoDB 只需要几分钟。
您操作数据库表的习惯可能也会是一个对性能影响很大的因素。比如: COUNT() 在 MyISAM 表中会非常快,而在InnoDB 表下可能会很痛苦。而主键查询则在InnoDB下会相当相当的快,但需要小心的是如果我们的主键太长了也会导致性能问题。大批的inserts 语句在MyISAM下会快一些,但是updates 在InnoDB 下会更快一些——尤其在并发量大的时候。
所以,到底你检使用哪一个呢?根据经验来看,如果是一些小型的应用或项目,那么MyISAM 也许会更适合。当然,在大型的环境下使用MyISAM 也会有很大成功的时候,但却不总是这样的。如果你正在计划使用一个超大数据量的项目,而且需要事务处理或外键支持,那么你真的应该直接使用InnoDB方 式。但需要记住InnoDB 的表需要更多的内存和存储,转换100GB 的MyISAM 表到InnoDB 表可能会让你有非常坏的体验。
第二篇:InnoDB还是MyISAM 再谈MySQL存储引擎的选择
作者:邵宗文,来源于:http://database.51cto.com/art/200905/124370.htm
两种类型最主要的差别就是Innodb 支持事务处理与外键和行级锁.而MyISAM不支持.所以MyISAM往往就容易被人认为只适合在小项目中使用。
我作为使用MySQL的用户角度出发,Innodb和MyISAM都是比较喜欢的,但是从我目前运维的数据库平台要达到需求:99.9%的稳定性,方便的扩展性和高可用性来说的话,MyISAM绝对是我的首选。
原因如下:
1、首先我目前平台上承载的大部分项目是读多写少的项目,而MyISAM的读性能是比Innodb强不少的。
2、MyISAM的索引和数据是分开的,并且索引是有压缩的,内存使用率就对应提高了不少。能加载更多索引,而Innodb是索引和数据是紧密捆绑的,没有使用压缩从而会造成Innodb比MyISAM体积庞大不小。
3、从平台角度来说,经常隔1,2个月就会发生应用开发人员不小心update一个表where写的范围不对,导致这个表没法正常用了,这个时候 MyISAM的优越性就体现出来了,随便从当天拷贝的压缩包取出对应表的文件,随便放到一个数据库目录下,然后dump成sql再导回到主库,并把对应的 binlog补上。如果是Innodb,恐怕不可能有这么快速度,别和我说让Innodb定期用导出xxx.sql机制备份,因为我平台上最小的一个数据 库实例的数据量基本都是几十G大小。
4、从我接触的应用逻辑来说,select count(*) 和order by 是最频繁的,大概能占了整个sql总语句的60%以上的操作,而这种操作Innodb其实也是会锁表的,很多人以为Innodb是行级锁,那个只是 where对它主键是有效,非主键的都会锁全表的。
5、还有就是经常有很多应用部门需要我给他们定期某些表的数据,MyISAM的话很方便,只要发给他们对应那表的frm.MYD,MYI的文件,让 他们自己在对应版本的数据库启动就行,而Innodb就需要导出xxx.sql了,因为光给别人文件,受字典数据文件的影响,对方是无法使用的。
6、如果和MyISAM比insert写操作的话,Innodb还达不到MyISAM的写性能,如果是针对基于索引的update操作,虽然MyISAM可能会逊色Innodb,但是那么高并发的写,从库能否追的上也是一个问题,还不如通过多实例分库分表架构来解决。
7、如果是用MyISAM的话,merge引擎可以大大加快应用部门的开发速度,他们只要对这个merge表做一些select count(*)操作,非常适合大项目总量约几亿的rows某一类型(如日志,调查统计)的业务表。
当然Innodb也不是绝对不用,用事务的项目如模拟炒股项目,我就是用Innodb的,活跃用户20多万时候,也是很轻松应付了,因此我个人也是很喜欢Innodb的,只是如果从数据库平台应用出发,我还是会首选MyISAM。
另外,可能有人会说你MyISAM无法抗太多写操作,但是我可以通过架构来弥补,说个我现有用的数据库平台容量:主从数据总量在几百T以上,每天十 多亿 pv的动态页面,还有几个大项目是通过数据接口方式调用未算进pv总数,(其中包括一个大项目因为初期memcached没部署,导致单台数据库每天处理 9千万的查询)。而我的整体数据库服务器平均负载都在0.5-1左右。
文章都不太长,适合着看看就行了。。
taobaoDBA关于MyISAM和InnoDB的插入性能的测试
Submitted by gouki on 2009, July 14, 7:10 AM
innodb和myisam两种类型的表,是mysql的基础表。很多人为了选择该使用哪 种表而头疼。
一般来说innodb对事务的支持比较好,而myisam则一般,innodb是行锁,mysql是表锁。但。。。下面这个测试却:
原文:http://rdc.taobao.com/blog/dba/html/295_insert_benchmark_for_myisam_and_innodb.html
作者:陶方
内容:
测试表结构:
CREATE TABLE `test` (
`ID` bigint(20) NOT NULL auto_increment,
`INT_A` int(11) default NULL,
`INT_B` int(11) default NULL,
`INT_C` int(11) default NULL,
`STRING_A` varchar(50) default NULL,
`STRING_B` varchar(250) default NULL,
`STRING_C` varchar(700) default NULL,
PRIMARY KEY (`ID`),
KEY `IDX_TEST_IA` (`INT_A`),
KEY `IDX_TEST_IB` (`INT_B`),
KEY `IDX_TEST_SA` (`STRING_A`,`INT_C`)
) ;
数据量:总共10个表,每个表插入400w数据
并发数:每个表并发20个线程去执行插入操作,总共200个线程
数据特点:除了主键采用自增外,索引相关字段全是随机生成的。字符串的长度和内容都是随机的,平均长度为预定义的一半
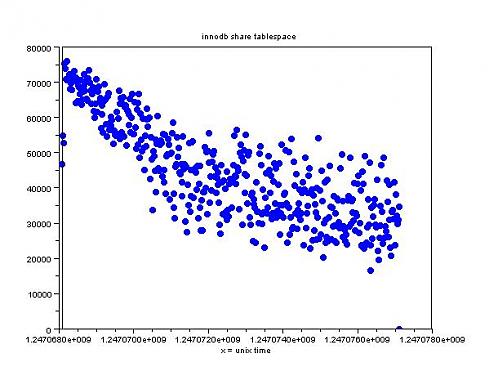
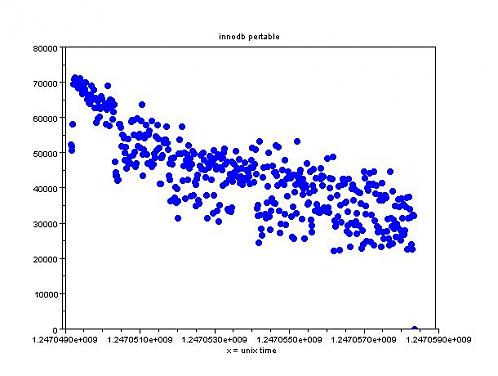
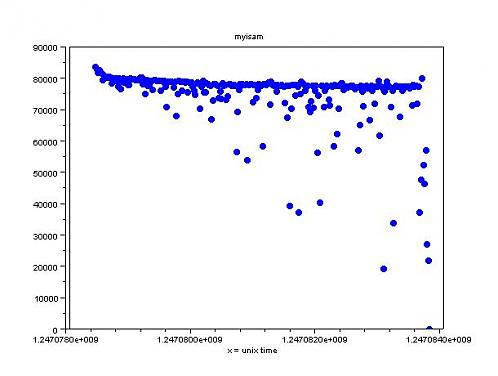
X轴是unix时间戳,Y轴是十秒钟的插入量。从以上测试结果可以看出,InnoDB的插入性能随着数据量的增多一直在下降,而且表现相当不稳定。MyISAM的表现还是比较好的,虽然瞬时插入的谷值一直在下降,但是整体表现很稳定。
总的来说,Ext3的cache算法性能还是非常不错的,不愧是linux上面备受推崇的文件系统。InnoDB虽然提供了高可用性,但是插入性能方面的表现并不如MyISAM稳定。
--EOF--
对于这个图是什么生成的,我也很有兴趣。。。。目前未知
discuz数据表优化
Submitted by gouki on 2009, June 22, 9:09 PM
这是来自imysql.cn的文章,作者是叶金荣,第一部分内容是3年前的了。可略作参考,估计7.0的数据库应该已经部分解决这个问题,第二部分是最新的。或许也能帮助你解决一些问题。
对于我来说是不用的啦。。我的论坛才几十个人。根本不需要用到这些功能。哇哈哈哈。
不过,我记得,如果是自己的服务器架设的论坛,DZ可以通过打开APC来进行缓存加速(好象是6.X版本中的功能。7.X没有研究过是不是还存在)
不说废话,看叶金荣先生的文章:
第一部分:
一. 前言
近日由于需要,对discuz论坛(简称dz)进行优化,当然了,只是涉及到数据库的优化.
先说一下服务器及dz的数据量,2 * Intel(R) Xeon(TM) CPU 2.40GHz, 4GB mem, SCISC硬盘.
MySQL 版本为 4.0.23. 数据表情况:
cdb_attachments 2万
cdb_members 10万
cdb_posts 68万
cdb_threads 7万
二. 缓存优化
在 my.cnf 中添加/修改以下选项:
#取消文件系统的外部锁
skip-locking
#不进行域名反解析,注意由此带来的权限/授权问题
skip-name-resolve
#索引缓存,根据内存大小而定,如果是独立的db服务器,可以设置高达80%的内存总量
key_buffer = 512M
#连接排队列表总数
back_log = 200
max_allowed_packet = 2M
#打开表缓存总数,可以避免频繁的打开数据表产生的开销
table_cache = 512
#每个线程排序所需的缓冲
sort_buffer_size = 4M
#每个线程读取索引所需的缓冲
read_buffer_size = 4M
#MyISAM表发生变化时重新排序所需的缓冲
myisam_sort_buffer_size = 64M
#缓存可重用的线程数
thread_cache = 128
#查询结果缓存
query_cache_size = 128M
#设置超时时间,能避免长连接
set-variable = wait_timeout=60
#最大并发线程数,cpu数量*2
thread_concurrency = 4
#记录慢查询,然后对慢查询一一优化
log-slow-queries = slow.log
long_query_time = 1
#关闭不需要的表类型,如果你需要,就不要加上这个
skip-bdb
以上参数根据各自服务器的配置差异进行调整,仅作为参考.
三. 索引优化
上面提到了,已经开启了慢查询,那么接下来就要对慢查询进行逐个优化了.
1. 搜索优化
搜索的查询SQL大致如下:
SELECT t.* FROM cdb_posts p, cdb_threads t WHERE
t.fid IN ('37', '45', '4', '6', '17', '41', '28', '32', '31', '1', '42')
AND p.tid=t.tid AND p.author LIKE 'JoansWin'
GROUP BY t.tid ORDER BY lastpost DESC LIMIT 0, 80;
用 EXPLAIN 分析的结果如下:
mysql>EXPLAIN SELECT t.* FROM cdb_posts p, cdb_threads t WHERE
t.fid IN ('37', '45', '4', '6', '17', '41', '28', '32', '31', '1', '42')
AND p.tid=t.tid AND p.author LIKE 'JoansWin'
GROUP BY t.tid ORDER BY lastpost DESC LIMIT 0, 80;
+-----------+------------+----------+--------------+-------------+-----------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra
+-----------+------------+----------+--------------+-------------+-----------+-------------+
| 1 | SIMPLE | t | range | PRIMARY,fid | fid | 2 | NULL | 66160 | Using where;
Using temporary; Using filesort |
| 1 | SIMPLE | p | ref | tid | tid | 3 | Forum.t.tid | 10 | Using where
| +----+-------------+-------+-------+---------------+------+---------+-------------+-------+
---------
只用到了 t.fid 和 p.tid,而 p.author 则没有索引可用,总共需要扫描
66160*10 = 661600 次索引,够夸张吧 :(
再分析 cdb_threads 和 cdb_posts 的索引情况:
mysql>show index from cdb_posts;
+-----------+------------+----------+--------------+-------------+-----------+----------
---+----------+--------+------+--+
| Table | Non_unique | Key_name | Seq_in_index | Column_name | Collation | Cardinality | Sub_part |
Packed | Null | Index_type | Comment | +-----------+------------+----------+--------------+----
---------+-----------+-------------+----------+--------+------+--+
| cdb_posts | 0 | PRIMARY | 1 | pid | A | 680114 | NULL | NULL |
| BTREE | |
| cdb_posts | 1 | fid | 1 | fid | A | 10 | NULL | NULL |
| BTREE | |
| cdb_posts | 1 | tid | 1 | tid | A | 68011 | NULL | NULL |
| BTREE | |
| cdb_posts | 1 | tid | 2 | dateline | A | 680114 | NULL | NULL |
| BTREE | |
| cdb_posts | 1 | dateline | 1 | dateline | A | 680114 | NULL | NULL |
| BTREE | |
+-----------+------------+----------+--------------+-------------+-----------+---
以及
mysql>show index from cdb_threads;
+-----------+------------+----------+--------------+-------------+-----------+-------------+
----------+--------+------+-----+
| Table | Non_unique | Key_name | Seq_in_index | Column_name | Collation | Cardinality | Sub_part |
Packed | Null | Index_type | Comment | +-----------+------------+----------+--------------+-----
--------+-----------+-------------+----------+--------+------+-----+
| cdb_threads | 0 | PRIMARY | 1 | tid | A | 68480 | NULL | NULL |
| BTREE | |
| cdb_threads | 1 | lastpost | 1 | topped | A | 4 | NULL | NULL |
| BTREE | |
| cdb_threads | 1 | lastpost | 2 | lastpost | A | 68480 | NULL | NULL |
| BTREE | |
| cdb_threads | 1 | lastpost | 3 | fid | A | 68480 | NULL | NULL |
| BTREE | |
| cdb_threads | 1 | replies | 1 | replies | A | 233 | NULL | NULL |
| BTREE | |
| cdb_threads | 1 | dateline | 1 | dateline | A | 68480 | NULL | NULL |
| BTREE | |
| cdb_threads | 1 | fid | 1 | fid | A | 10 | NULL | NULL |
| BTREE | |
| cdb_threads | 1 | enablehot | 1 | enablehot | A | 2 | NULL | NULL |
| BTREE | | +-------------+------------+-----------+--------------+-------------+------
看到索引 fid 和 enablehot 基数太小,看来该索引完全没必要,不过,对于fid基数较大的情况,则可能需要保留>该索引.
所做修改如下:
ALTER TABLE `cdb_threads` DROP INDEX `enablehot`, DROP INDEX `fid`, ADD INDEX (`fid`, `lastpost`);
ALTER TABLE `cdb_posts` DROP INDEX `fid`, ADD INDEX (`author`(10));
OPTIMIZE TABLE `cdb_posts`;
OPTIMIZE TABLE `cdb_threads`;
在这里, p.author 字段我设定的部分索引长度是 10, 是我经过分析后得出来的结果,不同的系统,这里的长度也不同,最好自己先取一下平均值,然后再适当调整.
现在,再来执行一次上面的慢查询,发现时间已经从 6s 变成 0.19s,提高了 30 倍.
这次先到这里,下次继续 ^_^
第二部分:
很早以前写过一个文章,是关于discuz论坛的优化:MySQL优化 之 Discuz论坛优化。 写的时候是2006年,没想到过了这么久,discuz论坛的问题还是困扰着很多网友,其实从各论坛里看到的问题总结出来,很关键的一点都是因为没有将数 据表引擎转成InnoDB导致的,discuz在并发稍微高一点的环境下就表现的非常糟糕,产生大量的锁等待,这时候如果把数据表引擎改成InnoDB的 话,我相信会好很多。这次就写个扫盲贴吧。
1. 启用innodb引擎,并配置相关参数
#skip-innodb
innodb_additional_mem_pool_size = 16M #一般16M也够了,可以适当调整下
innodb_buffer_pool_size = 6G #如果是专用db的话,一般是内存总量的80%
innodb_data_file_path = ibdata1:1024M:autoextend
innodb_file_io_threads = 4
innodb_thread_concurrency = 20
innodb_flush_log_at_trx_commit = 1
innodb_log_buffer_size = 16M
innodb_log_file_size = 256M
innodb_log_files_in_group = 3
innodb_max_dirty_pages_pct = 50
innodb_lock_wait_timeout = 120
innodb_file_per_table
2. 修改表引擎为innodb
mysql> alter table cdb_access engine = innodb;
其他表类似上面,把表名换一下即可...
将表存储引擎改成innodb后,不仅可以避免大量的锁等待,还可以提升查询的效率,因为innodb会把data和index都放在buffer pool中,效率更高。
膘叔认为:如果有自己的服务器,可以考虑做几件事情
1、如果有APC功能打开APC
2、如果没有APC,可以考虑把缓存目录指定为内存看看
3、GZIP关闭,少用rewrite等
4、在大负载的情况下,又只有一台服务器,考虑改程序,延迟插入或者其他的。。。(不太现实,哈哈)
| « 2024年04月 » | ||||||
| 日 | 一 | 二 | 三 | 四 | 五 | 六 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 | ||||
日志分类
- PHP
 [641]
[641] - python [9]
- Go [38]
- Flutter [14]
- lua [2]
- Scala [10]
- Javascript [298]
- PHP Framework [64]
- Linux [275]
- 苹果相关 [224]
- DataBase [161]
- Software [234]
- Literature [9]
- Ideas [22]
- 產品 [12]
- Misc [960]
- Baby [92]
热门标签
-
mysql
php
jquery
yii
ubuntu
google
linux
javascript
firefox
肖佑阳
framework
phpstorm
database
mac
thinkphp
svn
apache
zend
typecho
wordpress
qq
连载
seo
chrome
优化
ipad
netbeans
ios
css
架构
日志归档
搜索文章
最新评论
- Thanks for finally talking about...
02-27 - 将PDF转换为PNG - 大佬你好,在用dcat 遇到 怎么做无感刷新的问题,请问你有做过...
02-01 - uc5bbl8s - 好用!!
07-14 - 口水 - 发上来共享一下啊---这个就是在7的基础上做了一些改进而已
04-25 - guest - 大佬你这个改完后,不支持低版本了,容错不行啊----还要低版本兼...
04-25 - guest
博客信息
- 分类数量: 17
- 文章数量: 3067
- 评论数量: 1908
- 标签数量: 2249
- 附件数量: 942
- 注册用户: 56
- 今日访问: 32584
- 总访问量: 44266883
- 程序版本: 1.6